Given a file containing two header rows akin to 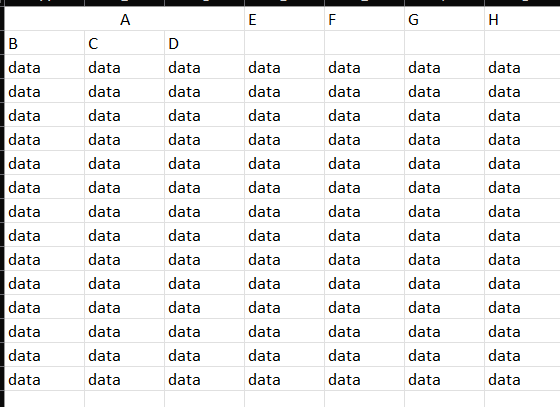
is there a way I can arrive at column names B, C, D, E, F, G either completely omitting A or prefixing it to B, C, D using pandas read_excel function without setting them manually using names argument?
>Solution :
You can read the spreadsheet with a MultiIndex header, then conditionally flatten it :
df = (
(tmp:=pd.read_excel("file.xlsx", header=[0, 1]))
.set_axis([c0 if c1.startswith("Unnamed") else c1 # to ommit A
# and if you need to concatenate both levels, use `else f"{c0}-{c1}"`
for (c0, c1) in tmp.columns], axis=1)
)
Output :
print(df)
B C D E F G H
0 data data data data data data data
1 data data data data data data data
2 data data data data data data data
3 data data data data data data data
4 data data data data data data data
5 data data data data data data data
6 data data data data data data data
7 data data data data data data data
8 data data data data data data data
9 data data data data data data data
10 data data data data data data data
11 data data data data data data data
12 data data data data data data data
13 data data data data data data data
With a prefix :
A-B A-C A-D E F G H
0 data data data data data data data
1 data data data data data data data
2 data data data data data data data
3 data data data data data data data
4 data data data data data data data
5 data data data data data data data
6 data data data data data data data
7 data data data data data data data
8 data data data data data data data
9 data data data data data data data
10 data data data data data data data
11 data data data data data data data
12 data data data data data data data
13 data data data data data data data