My input is a dataframe :
import pandas as pd
df = pd.DataFrame({'ID': ['ID001', 'ID001', 'ID001', 'ID002'],
'N1': [1, 1, 2, 1],
'N2': [1, 2, 1, 3],
'SUB_GROUP': [2, 2, 2, 1],
'CHUNK': [2, 2, 2, 4]})
I’m trying to add some rows (blue ones in the image below) based on the values of the columns SUB_GROUP and CHUNK. For example for ID002, the dataframe has only one row N1=1 and N2=3 and since this id must have one subgroup with 4 units each, then we add 1/1, 1/2 and 1/4.
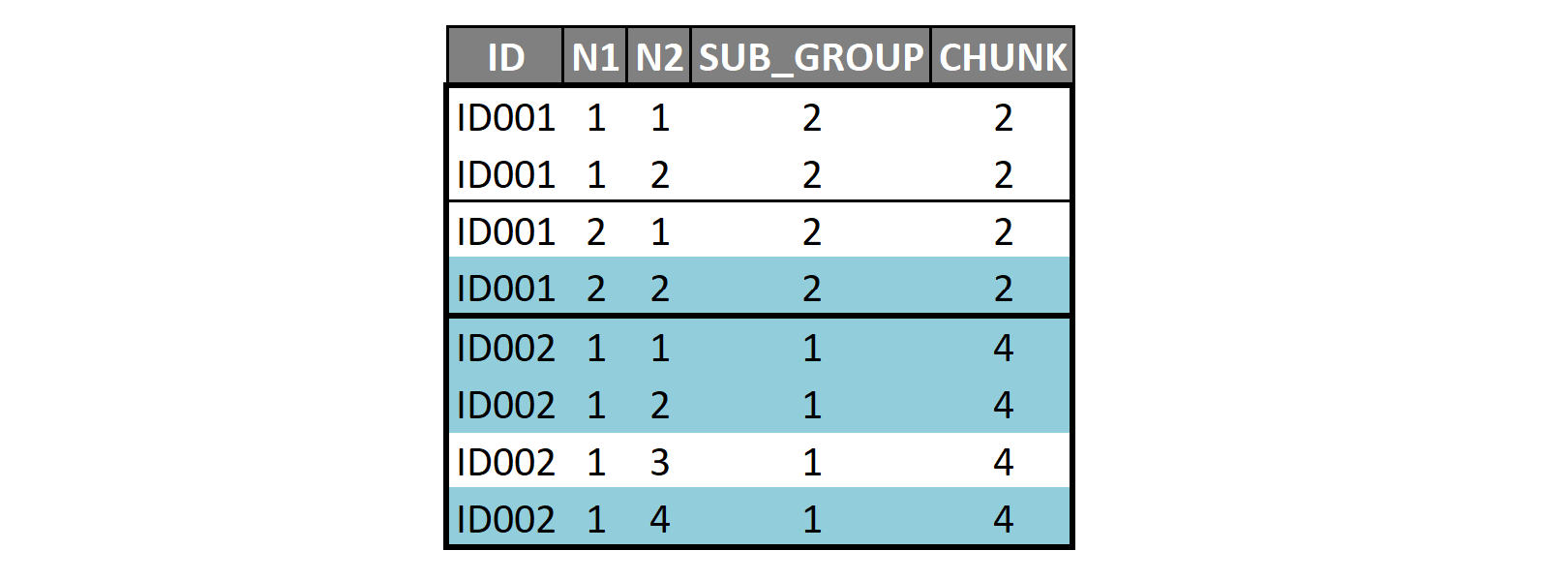
I was able to generate almost the new rows to add but can’t find a way to merge them in my df :
for id in df['ID'].unique():
new_rows = []
df1 = df.loc[df['ID'] == id]
len_sub_group = df1['SUB_GROUP'].iat[0]
len_chunk = df1['CHUNK'].iat[0]
for list1 in [list(n) for n in df1[['N1', 'N2']].values]:
list1 = list([tuple(list1)])
new_rows = [(len_sub_group, i)
for i in range(1, len_chunk + 1)
if (len_sub_group, i) not in list1]
Do you guys have an idea to do that ?
>Solution :
You could use a custom groupby.apply with itertools.product and merge:
from itertools import product
cols = ['ID', 'SUB_GROUP', 'CHUNK']
def add_missing(g):
p =product(range(1, g['SUB_GROUP'].iat[0]+1),
range(1, g['CHUNK'].iat[0]+1),
)
return g.merge(
pd.DataFrame(p,
columns=['N1', 'N2']),
how='right'
)
out = (df.groupby(cols)[list(df)]
.apply(add_missing).drop(columns=cols)
.reset_index(cols)[list(df)]
)
Output:
ID N1 N2 SUB_GROUP CHUNK
0 ID001 1 1 2 2
1 ID001 1 2 2 2
2 ID001 2 1 2 2
3 ID001 2 2 2 2
0 ID002 1 1 1 4
1 ID002 1 2 1 4
2 ID002 1 3 1 4
3 ID002 1 4 1 4