How to create pyspark dataframe from a dict with tuple as value?
[['HNN', (0.5083874458874459, 56)], ['KGB', (0.7378654301578141, 35)], ['KHB', (0.6676891615541922, 18)]]
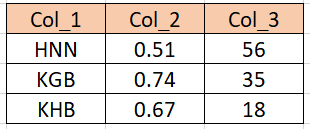
The output should looks sth like that (please see attached ss)
>Solution :
The simplest way I can think of is to merge the string and tuple within each list.
This can be accomplished with list comrehension where you take element 0 (the string) and unpack element 1 (the tuple) using * into a list for each list in your list of lists.
l= [['HNN', (0.5083874458874459, 56)], ['KGB', (0.7378654301578141, 35)], ['KHB', (0.6676891615541922, 18)]]
df = spark.createDataFrame([[x[0],*x[1]] for x in l], ['col_1','col_2','col_3'])
Output
+-----+------------------+-----+
|col_1| col_2|col_3|
+-----+------------------+-----+
| HNN|0.5083874458874459| 56|
| KGB|0.7378654301578141| 35|
| KHB|0.6676891615541922| 18|
+-----+------------------+-----+