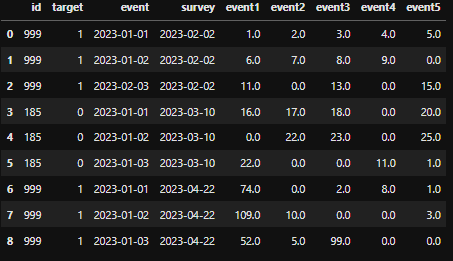
I have Data Frame in Python Pandas like below:
df = pd.DataFrame({
'id' : [999, 999, 999, 185, 185, 185, 999, 999, 999],
'target' : [1, 1, 1, 0, 0, 0, 1, 1, 1],
'event': ['2023-01-01', '2023-01-02', '2023-02-03', '2023-01-01', '2023-01-02', '2023-01-03', '2023-01-01', '2023-01-02', '2023-01-03'],
'survey': ['2023-02-02', '2023-02-02', '2023-02-02', '2023-03-10', '2023-03-10', '2023-03-10', '2023-04-22', '2023-04-22', '2023-04-22'],
'event1': [1, 6, 11, 16, np.nan, 22, 74, 109, 52],
'event2': [2, 7, np.nan, 17, 22, np.nan, np.nan, 10, 5],
'event3': [3, 8, 13, 18, 23, np.nan, 2, np.nan, 99],
'event4': [4, 9, np.nan, np.nan, np.nan, 11, 8, np.nan, np.nan],
'event5': [5, np.nan, 15, 20, 25, 1, 1, 3, np.nan]
})
df = df.fillna(0)
df
Requirements:
And I need to remain in my Data Frame not duplicated values in column "id" remaining also all rows with not duplicated values from column "survey" for that id.
So, for example as you can see in example for id = 999 we have in column "survey" value 2023-02-02 or 2023-04-22, so I need to stay all rows for id = 999 with 2023-02-02 or with 2023-04-022.
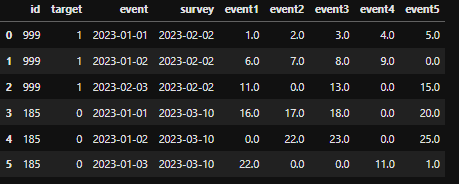
Example of needed result:
So, as a result I need something like below:
df = pd.DataFrame({
'id' : [999, 999, 999, 185, 185, 185],
'target' : [1, 1, 1, 0, 0, 0],
'event': ['2023-01-01', '2023-01-02', '2023-02-03', '2023-01-01', '2023-01-02', '2023-01-03'],
'survey': ['2023-02-02', '2023-02-02', '2023-02-02', '2023-03-10', '2023-03-10', '2023-03-10'],
'event1': [1, 6, 11, 16, np.nan, 22],
'event2': [2, 7, np.nan, 17, 22, np.nan],
'event3': [3, 8, 13, 18, 23, np.nan],
'event4': [4, 9, np.nan, np.nan, np.nan, 11],
'event5': [5, np.nan, 15, 20, 25, 1]
})
df = df.fillna(0)
df
How can I do that in Python Pandas ?
>Solution :
You can keep the first survey date per id with groupby.transform:
out = df[df.groupby('id')['survey'].transform('first').eq(df['survey'])]
Output:
id target event survey event1 event2 event3 event4 event5
0 999 1 2023-01-01 2023-02-02 1.0 2.0 3.0 4.0 5.0
1 999 1 2023-01-02 2023-02-02 6.0 7.0 8.0 9.0 0.0
2 999 1 2023-02-03 2023-02-02 11.0 0.0 13.0 0.0 15.0
3 185 0 2023-01-01 2023-03-10 16.0 17.0 18.0 0.0 20.0
4 185 0 2023-01-02 2023-03-10 0.0 22.0 23.0 0.0 25.0
5 185 0 2023-01-03 2023-03-10 22.0 0.0 0.0 11.0 1.0