I have a list of webid that I want to scrape from WikiData website. Here are the two links as an example.
https://www.wikidata.org/wiki/Special:EntityData/Q317521.jsonld
https://www.wikidata.org/wiki/Special:EntityData/Q478214.jsonld
I only need the first set of "P31" from the URL. For the first URL, the information that I need will be "wd:Q5" and second URL will be ["wd:Q786820", "wd:Q167037", "wd:Q6881511","wd:Q4830453","wd:Q431289","wd:Q43229","wd:Q891723"] and store them into a list.
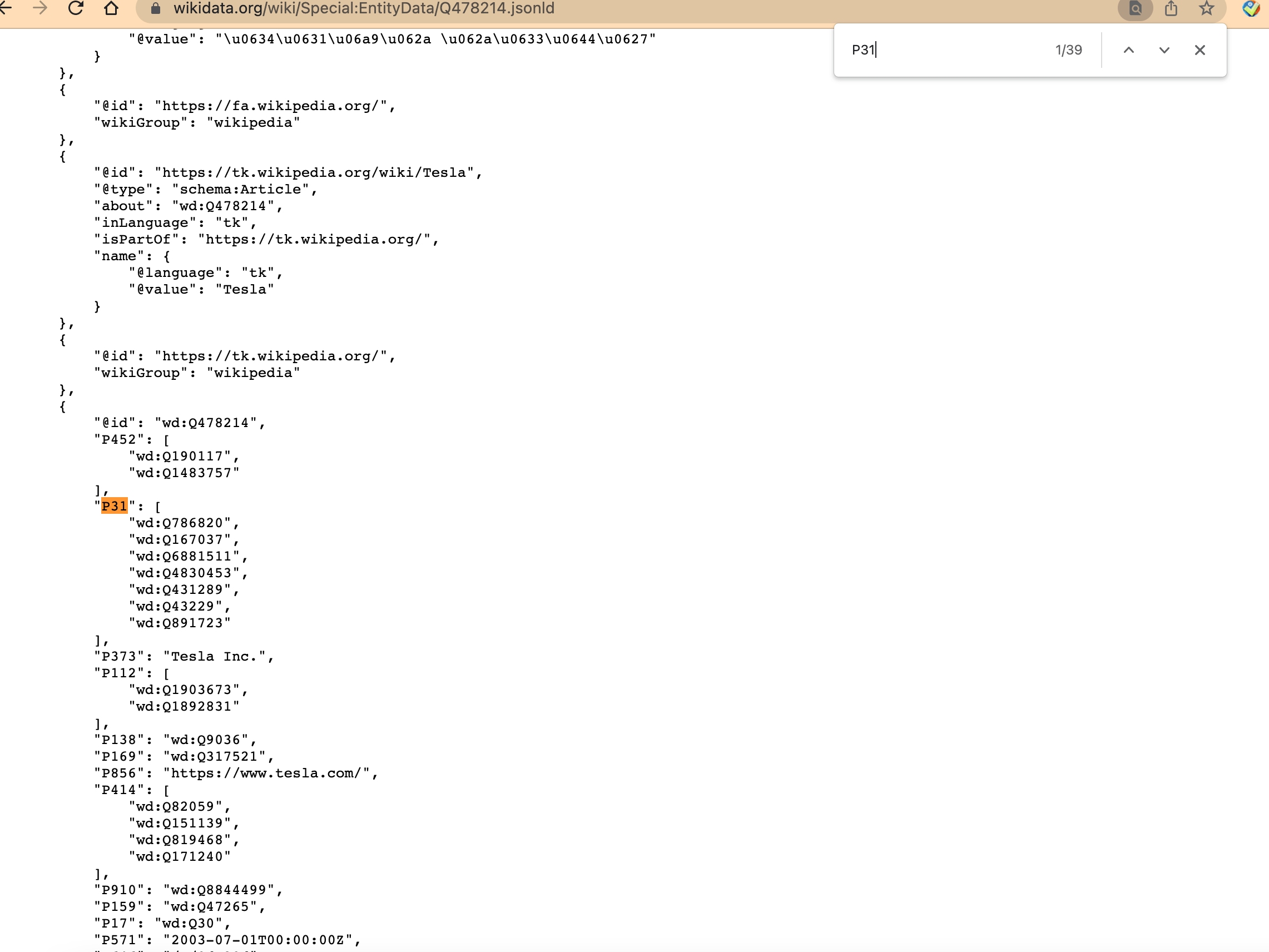
When I use find and input "P31", I only need the first results out of all the results. The picture above illustrate it
The output will look like this.
info = ['wd:Q5',
["wd:Q786820", "wd:Q167037", "wd:Q6881511","wd:Q4830453","wd:Q431289","wd:Q43229","wd:Q891723"],
]
lst = ["Q317521","Q478214"]
for q in range(len(lst)):
link =f'https://www.wikidata.org/wiki/Special:EntityData/{q}.jsonld'
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
After that, I do not know how to extract the information from the first set of "P31". I am using request, BeautifulSoup, and Selenium libraries but I am wondering are there any better ways to scrape/extract that information from the URL besides using XPath or Class?
Thank you so much!
>Solution :
You only need requests as you are getting a JSON response.
You can use a function which loops the relevant JSON nested object and exits at first occurrence of target key whilst appending the associated value to your list.
The loop variable should be the id to add into the url for the request.
import requests
lst = ["Q317521","Q478214"]
info = []
def get_first_p31(data):
for i in data['@graph']:
if 'P31' in i:
info.append(i['P31'])
break
with requests.Session() as s:
s.headers = {"User-Agent": "Safari/537.36"}
for q in lst:
link =f'https://www.wikidata.org/wiki/Special:EntityData/{q}.jsonld'
try:
r = s.get(link).json()
get_first_p31(r)
except:
print('failed with link: ', link)