I have the following list of file paths. The data folder has sub folders with names as ID and each subfolder contains data files.
library(dplyr)
library(stringr)
library(tidyr)
paths <- c(
"data/A101/usage.xlsx",
"data/A101/cost.xls",
"data/A101/A101 cost-1.csv",
"data/B202/B202 data.csv",
"data/B202/cost1.xlsx",
"data/C303/usage1.xls",
"data/D404/cost1.csv",
"data/D404/D404 data1.xlsx",
"data/E/E data1.csv"
)
I want to create a data frame that looks like this: site_id from the names of sub folders, file_name_1 … file_name_n with the extracted file names from each folder. file_name_1 should contain all names of the first files from each site, file_name_2 should contain all of the 2nd extracted file names (if exists), and so on.
df <- data.frame(
site_id = unique(str_extract(paths, "[A-D]\\d+|E")),
file_name_1 = c("usage.xlsx", "B202 data.csv", "usage1.xls", "cost1.csv", "data1.csv"),
file_name_2 = c("cost.xls", "cost1.xlsx", NA, "D404 data1.xlsx", NA),
file_name_3 = c("A101 cost-1.csv", NA, NA, NA, NA)
)
And I have tried the following:
test <- data.frame(
site_id = str_extract(paths, "[A-D]\\d+|E"),
file_name = str_extract(paths, "[^\\/]+$")
) %>%
gather(key=key, value=value, -site_id) %>%
pivot_wider(
id_cols = "site_id",
names_from = key,
values_from = value,
names_glue = "{key}_{seq_along({key})}",
values_fn = list
)
View(test)
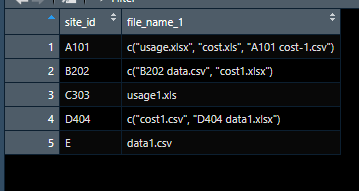
The result has only one column with the file names combined into a vector. What am I missing here?
>Solution :
Please try the below code
df <- data.frame(paths=paths) %>%
separate(paths, into = c('new','site_id', 'file'), sep = '/') %>%
mutate(row=paste0('file_name_',row_number()),
.by=site_id) %>%
pivot_wider(id_cols = site_id, names_from = row,values_from = file)
Created on 2023-07-19 with reprex v2.0.2
# A tibble: 5 × 4
site_id file_name_1 file_name_2 file_name_3
<chr> <chr> <chr> <chr>
1 A101 usage.xlsx cost.xls A101 cost-1.csv
2 B202 B202 data.csv cost1.xlsx <NA>
3 C303 usage1.xls <NA> <NA>
4 D404 cost1.csv D404 data1.xlsx <NA>
5 E E data1.csv <NA> <NA>