Shown below are few details on a DataFrame.
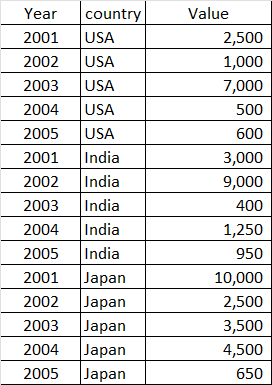
Below is the syntax that is been used and do not get the expected output.
df = df.sort_values(by=['country','Year','Value'], ascending=[True,True,False])
df = df.drop_duplicates('country')
how could I get the expected output shown below

>Solution :
Try sorting by "Value" and keeping the last row for each country
>>> df.sort_values("Value").drop_duplicates("country",keep="last")
Year country Value
2 2003 USA 7000
6 2002 India 9000
10 2001 Japan 10000
Alternatively, you could use groupby:
>>> df[df["Value"].eq(df.groupby("country")["Value"].transform('max'))]
Year country Value
2 2003 USA 7000
6 2002 India 9000
10 2001 Japan 10000