I have a df that looks like following. I would like to find the closest date (from R_1:R_10) that happened before date. Is it a way to calculate the difference in days for R1:R10 to date at once and then pick out the the value we want, and then put it in a new variable cdate?
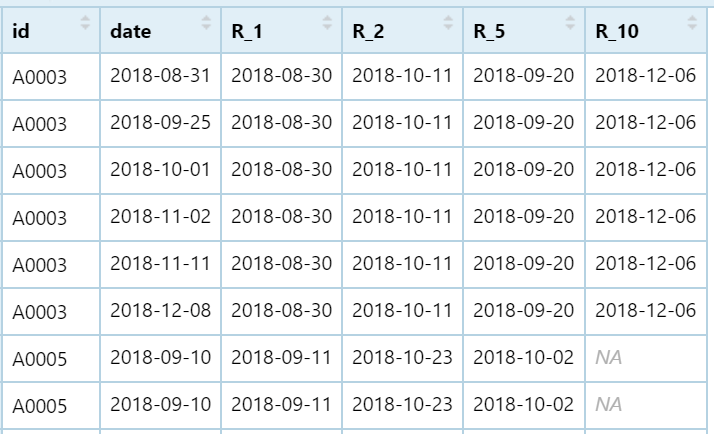
the output will looks like this:
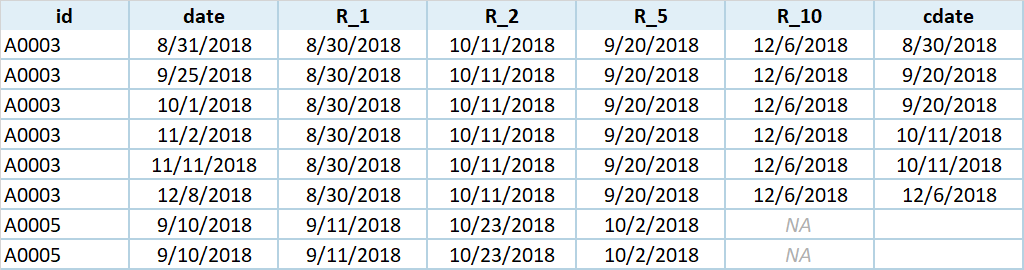
the cdate will be identified by R_1:R10-date, whichever has the greatest negative value will be the date that we put in cdate
Sample data:
df<-structure(list(id = c("A0003", "A0003", "A0003", "A0003", "A0003",
"A0003", "A0005", "A0005"), date = structure(c(17774, 17799,
17805, 17837, 17846, 17873, 17784, 17784), class = "Date"), R_1 = structure(c(17773,
17773, 17773, 17773, 17773, 17773, 17785, 17785), class = "Date"),
R_2 = structure(c(17815, 17815, 17815, 17815, 17815, 17815,
17827, 17827), class = "Date"), R_5 = structure(c(17794,
17794, 17794, 17794, 17794, 17794, 17806, 17806), class = "Date"),
R_10 = structure(c(17871, 17871, 17871, 17871, 17871, 17871,
NA, NA), class = "Date")), row.names = c(NA, 8L), class = "data.frame")
>Solution :
With base R, we loop over the ‘R_’ columns with lapply, replace the values that are greater than ‘date’ to NA, then use pmax to return the max date value
df$cdate <- do.call(pmax, c(lapply(df[grep("R_", names(df))],
\(x) replace(x, x > df$date, NA)), na.rm = TRUE))
-output
> df
id date R_1 R_2 R_5 R_10 cdate
1 A0003 2018-08-31 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-08-30
2 A0003 2018-09-25 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-09-20
3 A0003 2018-10-01 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-09-20
4 A0003 2018-11-02 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-10-11
5 A0003 2018-11-11 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-10-11
6 A0003 2018-12-08 2018-08-30 2018-10-11 2018-09-20 2018-12-06 2018-12-06
7 A0005 2018-09-10 2018-09-11 2018-10-23 2018-10-02 <NA> <NA>
8 A0005 2018-09-10 2018-09-11 2018-10-23 2018-10-02 <NA> <NA>