I have the data frame below. I want to get a create a new column called rank that ranks the stock by growth for each year and sector.
import pandas as pd
d = {'date': [2000, 2000, 2001, 2001, 2002, 2002, 2003, 2003, 2004, 2004], 'Stock': ["GM", "F", "GM", "F", "GM", "F", "GM", "F", "GM", "F"], 'US Sales Growth': [.3, .3, .1, .1, .6, .6, .12, .12, .7, .7], 'Stock_Growth': [.1, .2, .3, .4, .14, .16, .2, .1,.15,.16]}
df = pd.DataFrame(data=d)
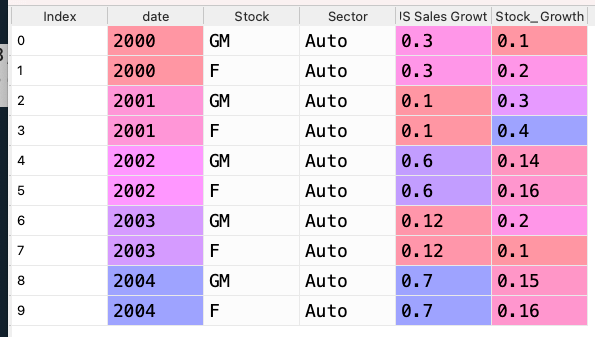
It should look like this.
d = {'date': [2000, 2000, 2001, 2001, 2002, 2002, 2003, 2003, 2004, 2004], 'Stock': ["GM", "F", "GM", "F", "GM", "F", "GM", "F", "GM", "F"], 'Sector': ['Auto', 'Auto', 'Auto', 'Auto', 'Auto', 'Auto', 'Auto', 'Auto', 'Auto', 'Auto'], 'US Sales Growth': [.3, .3, .1, .1, .6, .6, .12, .12, .7, .7], 'Stock_Growth': [.1, .2, .3, .4, .14, .16, .2, .1,.15,.16], 'Rank': [2, 1, 2, 1, 2, 1, 1, 2, 2, 1]}
df2 = pd.DataFrame(data=d)
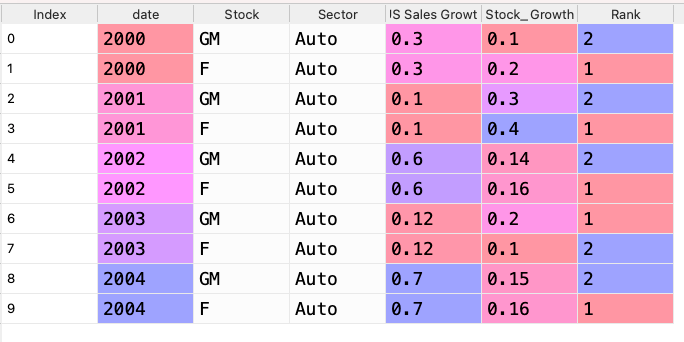
I tried doing this but just gave me NANs
df['place_holder'] = df.groupby(['Stock','date'], as_index=False)['Stock_Growth'].transform(lambda x: x.shift(1))
df['rank'] = df.groupby('date', as_index=False)['place_holder'].transform(lambda x: x.rank())
Another way of doing it was get groupby date first then sector and then rank them.
>Solution :
Using groupby and then apply another step to rank each group seems the right approach. I recommend using the rank method of a Groupby object to compute the rank of the values of a column in each group. This means, that this should provide the expected output:
>> df["Rank"] = df.groupby(["date", "Sector"])["Stock_Growth"].rank(ascending=False)
>> df
date Stock US Sales Growth Stock_Growth Sector Rank
0 2000 GM 0.30 0.10 Auto 2.0
1 2000 F 0.30 0.20 Auto 1.0
2 2001 GM 0.10 0.30 Auto 2.0
3 2001 F 0.10 0.40 Auto 1.0
4 2002 GM 0.60 0.14 Auto 2.0
5 2002 F 0.60 0.16 Auto 1.0
6 2003 GM 0.12 0.20 Auto 1.0
7 2003 F 0.12 0.10 Auto 2.0
8 2004 GM 0.70 0.15 Auto 2.0
9 2004 F 0.70 0.16 Auto 1.0
The ascending=False part ensures that higher values get a better (lower) rank.