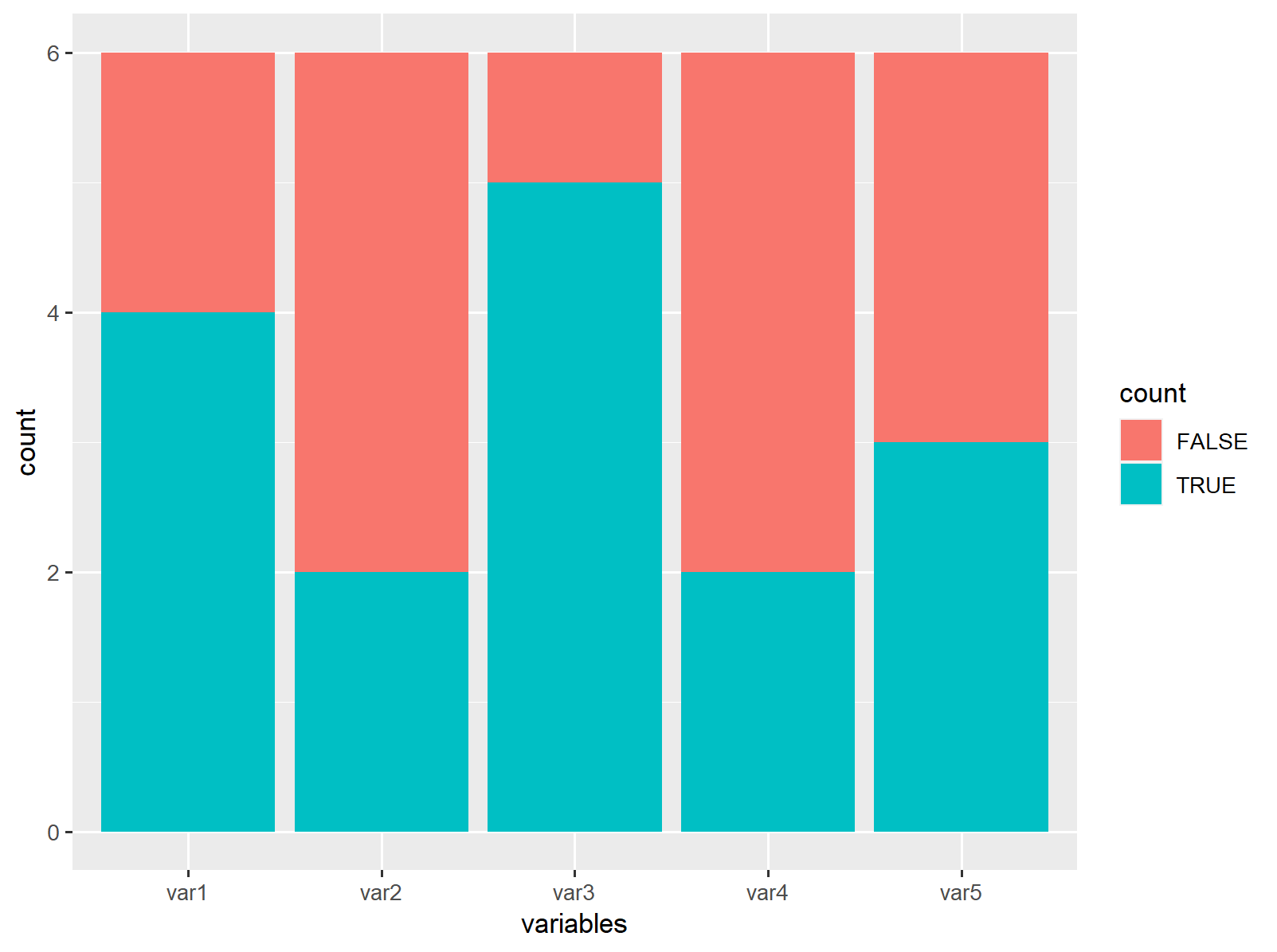
So I am attempting to replicate the following plot:
But instead of the class as listed here, I have 5 True or False Boolean variables and I would like each to populate each column, based on count of ID.
DATA
ID var1 var2 var3 var4 var5
001 TRUE FALSE TRUE FALSE TRUE
002 FALSE TRUE FALSE FALSE FALSE
003 TRUE FALSE TRUE TRUE TRUE
004 TRUE TRUE TRUE FALSE FALSE
005 TRUE FALSE TRUE TRUE TRUE
006 FALSE FALSE TRUE FALSE FALSE
The end goal should be:
- x-axis: Varibles, with each of the variables being a column
- y-axis: Count, with frequency values based on the count of the ID, aka number of rows.
- group: True or False.
This is what I think the resulting df may look like but not confident…
variables t_f count
var1 TRUE 4
var1 FALSE 2
var2 TRUE 2
var2 FALSE 4
var3 TRUE 5
var3 FALSE 1
var4 TRUE 2
var4 FALSE 4
var5 TRUE 3
var5 FALSE 3
>Solution :
Here is one way to do it. You do not have to manually compute the ys if it is just counting the rows. You can use geom_bar. Something like this
library(dplyr)
library(tidyr)
library(ggplot2)
df %>%
pivot_longer(-ID, names_to = "variables", values_to = "count") %>%
ggplot() +
geom_bar(aes(x = variables, fill = count), position = "stack")
Output