I have the following dataset
Books'Title Authors Publishing Year \
1 Il nome della rosa Umberto Eco 1980
2 L'amore che ti meriti Daria Bignardi 2014
3 Memorie dal sottsuolo Fëdor Dostoevskij 1864
4 Oblomov Ivan Alexandrovich Goncharov 1859
Publication House
1 Bompiani
2 Mondadori
3 Rizzoli
4 Feltrinelli
I have built it as follows:
data = [("Il nome della rosa","Umberto Eco", 1980),
("L'amore che ti meriti","Daria Bignardi", 2014),
("Memorie dal sottsuolo", " Fëdor Dostoevskij", 1864),
("Oblomov", "Ivan Alexandrovich Goncharov ", 1859)]
index = range(1,5,1)
data = pd.DataFrame(data, columns = ["Books'Title", "Authors", "Publishing Year"], index = index)
data
pubhouses = ["Bompiani", "Mondadori", "Rizzoli", "Feltrinelli"]
data.insert(3, 'Publication House', pubhouses)
data
I am trying adding new rows as follows in the 4th position but without changing the original index of the dataset. By following the suggestions of this website page Insert a row to pandas dataframe
new_row = ['Le avventure di Pinocchio', 'Carlo Collodi', 1883, 'Giunti']
new_row
for i in range(1, 6):
data.loc[-1] = new_row
data.index = data.index + 1
data = data.sort_index()
data
But I am getting the following dataset
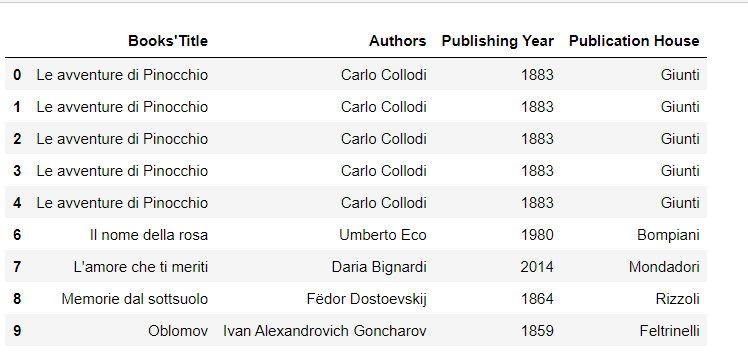
May I ask – since I am a beginner how to possibly perform this operation? How would it be possible to exchange the original index of the dataset?
Thanks
>Solution :
Because your index is numeric and loc and iloc are the same here (and only here), you can enlarge your dataframe easily:
data.loc[data.index[-1] + 1] = new_row
print(data)
# Output
Books'Title Authors Publishing Year Publication House
1 Il nome della rosa Umberto Eco 1980 Bompiani
2 L'amore che ti meriti Daria Bignardi 2014 Mondadori
3 Memorie dal sottsuolo Fëdor Dostoevskij 1864 Rizzoli
4 Oblomov Ivan Alexandrovich Goncharov 1859 Feltrinelli
5 Le avventure di Pinocchio Carlo Collodi 1883 Giunti
Else you have to build a dataframe and concatenate it:
df = pd.DataFrame([new_row], columns=data.columns)
data = pd.concat([data, df], ignore_index=True)
print(data)
# Output
Books'Title Authors Publishing Year Publication House
0 Il nome della rosa Umberto Eco 1980 Bompiani
1 L'amore che ti meriti Daria Bignardi 2014 Mondadori
2 Memorie dal sottsuolo Fëdor Dostoevskij 1864 Rizzoli
3 Oblomov Ivan Alexandrovich Goncharov 1859 Feltrinelli
4 Le avventure di Pinocchio Carlo Collodi 1883 Giunti