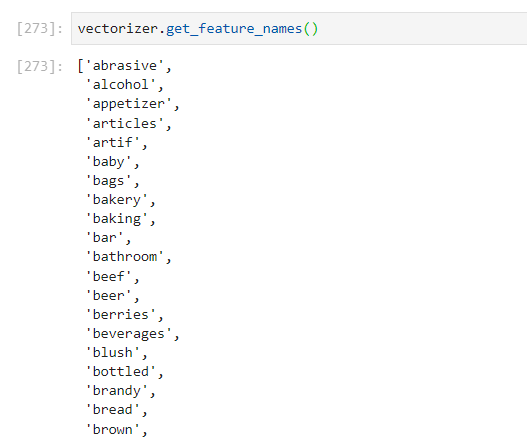
The dataframe I am talking about
is this
I am interested in only a subset of the products and I want to transform the data so instead of having "item" columns I have columns with the names of the products I am interested in with values of 0 or 1 indicating whether or not the said product is in the basket. What I have done so far is this
data_list = []
products = ['citrus fruit', 'tropical fruit', 'whole milk', 'other vegetables', 'rolls/buns', 'chocolate', 'bottled water', 'yogurt',
'sausage', 'root vegetables', 'pastry', 'soda', 'cream']
for i in range(raw_data.shape[0]):
entry = []
# discretize basket_value
if(raw_data.values[i, 1] < 5):
entry.append('low_value_basket')
elif(raw_data.values[i, 1] < 10):
entry.append('medium_value_basket')
else:
entry.append('high_value_basket')
# add recency_days
entry.append(raw_data.values[i, 2])
# add columns for the products specified with values of 1 (indicating the product is in the basket) and 0 (indicating it is not)
flag = False # flag used to determine if any of the specified products is in the basket
for j in range(len(products)):
value = 1 if products[j] in raw_data.values[i, 3:] else 0
entry.append(value)
if(value == 1) :
flag = True
if(flag):
data_list.append(entry)
However this takes several minutes to run (the raw_data has around 7,500 entries) and I was wondering if there was any faster way of doing it.
>Solution :
Use:
df = pd.DataFrame([['ab', 'bv', 'cc'], ['cc'], ['dv', 'ab', 'ac', 'ff']], columns = ['i1', 'i2', 'i3', 'i4'])
corpus = df.apply(lambda x: ' '.join(x.to_numpy().astype(str)), axis=1).values
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=0, use_idf = False)
X = vectorizer.fit_transform(corpus)
temp = X.toarray()>0
temp.astype(int)
Output:
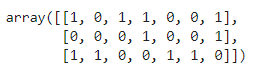
It is bag of items. If we print the following comment, it can be more clear:
vectorizer.get_feature_names()
Output:
['ab', 'ac', 'bv', 'cc', 'dv', 'ff', 'none']
We can see that the ‘ab’ item is present in the first basket and the second is not, and so on. Based on the data provided, I rewrite the answer:
df = pd.read_csv('GroceriesInitial.csv')
df = df.loc[:, [x for x in df.columns if 'Item' in x]]
corpus = df.apply(lambda x: ' '.join(x.to_numpy().astype(str)), axis=1).values
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=0, use_idf = False)
X = vectorizer.fit_transform(corpus)
temp = X.toarray()>0
temp.astype(int)
Output:
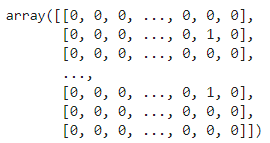
and corresponding items: