I have a following DataFrame:
| model | metric | final_result | score |
|---|---|---|---|
| Decision Tree | F1 | Pass | 0.57346 |
| Decision Tree | accuracy | Pass | 0.76512 |
| Decision Tree | precision | Pass | 0.6346 |
| Decision Tree | recall | Pass | 0.66512 |
| Decision Tree | F1 | Fail | 0.57346 |
| Decision Tree | accuracy | Fail | 0.76512 |
| Decision Tree | precision | Fail | 0.6346 |
| Decision Tree | recall | Fail | 0.66512 |
| RF | F1 | Pass | 0.57346 |
| RF | accuracy | Pass | 0.76512 |
| RF | precision | Pass | 0.6346 |
| RF | recall | Pass | 0.66512 |
| … | … | … | … |
I want to pivot the table to the following format:
| Decision Tree | Random Forest | ||
|---|---|---|---|
| final_result | metric | ||
| Pass | accuracy | 0.76512 | 0.76512 |
| precision | 0.6346 | 0.6346 | |
| recall | 0.66512 | 0.66512 | |
| F1 | 0.57436 | 0.57346 | |
| Fail | accuracy | 0.76512 | 0.76512 |
| precision | 0.6346 | 0.6346 | |
| recall | 0.66512 | 0.66512 | |
| F1 | 0.57436 | 0.57346 | |
| … | … | … | … |
I tried doing this by using the pivot_table function like this:
pd.pivot_table(modelPerformance, values='score', index=['metric', 'Final Result'], columns='model')
However, that leaves me with a "squashed" table that looks like this:
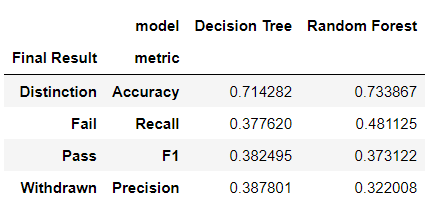
I’m stumped because it’s hard to explain this issue and find possible solutions online, so I’m hoping someone here will understand my end goal.
>Solution :
IIUC, use pivot instead of pivot_table:
>>> df.pivot(['final_result', 'metric'], 'model', 'score')
model Decision Tree RF
final_result metric
Fail F1 0.57346 NaN
accuracy 0.76512 NaN
precision 0.63460 NaN
recall 0.66512 NaN
Pass F1 0.57346 0.57346
accuracy 0.76512 0.76512
precision 0.63460 0.63460
recall 0.66512 0.66512