Good morning guys. So my problem is to remove duplicates from dataframe caused by many diffrent values in one of columns.
The base dataframe looks like this below:
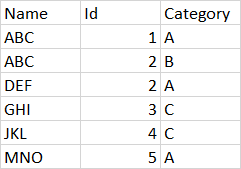
As You can see, I have duplicated values in columns Name and Id depends on Category.
Our goal is to remove those duplicates while keeping the information about category.
I would like to have the exact view as here below:
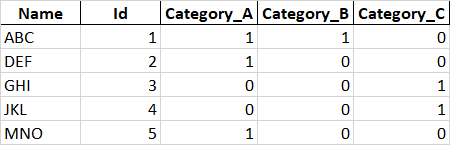
I have tried to use get_dummies method from pandas library but i have some issues.
dummies = pd.get_dummies(df[['Category']], drop_first=True)
df = pd.concat([df.drop(['Category'], axis=1), dummies], axis=1)
Using the code above i’m getting the result like this below:
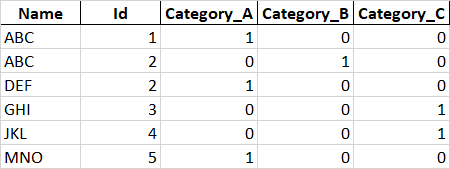
The result is basicly still the same as base dataframe.
Do You guys have any idea how to deal with it?
>Solution :
It depends what need – if possible duplicates per Name and Id is necessary aggregate max:
df = (pd.get_dummies(df, columns=['Category'])
.groupby(['Name','Id'], as_index=False)
.max())
print (df)
Name Id Category_A Category_B Category_C
0 ABC 1 1 0 0
1 ABC 2 0 1 0
2 DEF 2 1 0 0
3 GHI 3 0 0 1
4 JKL 4 0 0 1
5 MNO 5 1 0 0
If need aggregate per Id with last value for non numeric values use:
f = lambda x: x.max() if np.issubdtype(x.dtype, np.number) else x.iat[-1]
df = (pd.get_dummies(df, columns=['Category'])
.groupby('Id', as_index=False)
.agg(f))
print (df)
Id Name Category_A Category_B Category_C
0 1 ABC 1 0 0
1 2 DEF 1 1 0
2 3 GHI 0 0 1
3 4 JKL 0 0 1
4 5 MNO 1 0 0
In second solution is possible specify columns for aggregations:
# f = lambda x: x.max() if np.issubdtype(x.dtype, np.number) else x.iat[-1]
df = pd.get_dummies(df, columns=['Category'])
d = dict.fromkeys(df.columns, 'max')
d['Name'] = 'last'
print (d)
{'Name': 'last', 'Id': 'max', 'Category_A': 'max', 'Category_B': 'max', 'Category_C': 'max'}
df = df.groupby('Id', as_index=False).agg(d)
print (df)
Name Id Category_A Category_B Category_C
0 ABC 1 1 0 0
1 DEF 2 1 1 0
2 GHI 3 0 0 1
3 JKL 4 0 0 1
4 MNO 5 1 0 0