I have the dataset with top 100 richest people in the world.
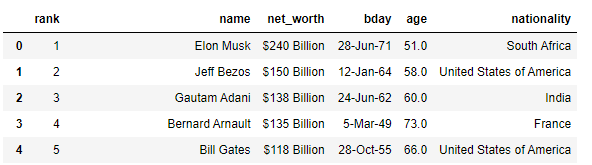
I want to group by "age" column, leave only max value in "net_worth" and have the third column – "name" of this person.
I could make two columns with code
df = df.groupby(['age']).agg({'net_worth': ['max']})
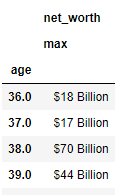
I want to have third column "name", but I don’t know how to do it
I tried
df = df.groupby(['age', 'name']).agg({'net_worth': ['max']})
But ‘name’ column involved in group.
I need smth like this:
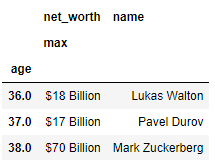
>Solution :
Use DataFrameGroupBy.idxmax with extract numbers from net_worth by Series.str.extract:
s = df['net_worth'].str.extract(r'(\d+)', expand=False).astype(int)
out = df.loc[s.groupby(df['age']).idxmax(),['net_worth','name','age']]
print (out.head())
net_worth name age
90 $18 Billion Lukas Walton 36.0
92 $17 Billion Pavel Durov 37.0
17 $70 Billion Mark Zuckerberg 38.0
30 $44 Billion Zhang Yiming 39.0
82 $19 Billion Eduardo Saverin 40.0