This is a follow up to this post
This is my DataFrame:
df = pd.DataFrame(
{
'a': [10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 10, 22],
'b': [1, 1, 1, -1, -1, -1, -1, 2, 2, 2, 2, -1, -1, -1, -1],
'c': [25, 25, 25, 45, 45, 45, 45, 65, 65, 65, 65, 40, 40, 30, 30],
'main': ['x', 'x', 'x', 'x', 'x', 'x', 'x', 'y', 'y', 'y', 'y', 'y', 'y', 'y', 'y']
}
)
Expected output: Groupby main AND c:
a b c main
0 10 1 25 x
1 15 1 25 x
2 20 1 25 x
3 25 -1 45 x
4 30 -1 45 x
5 35 -1 45 x
6 40 -1 45 x
11 65 -1 40 y
12 70 -1 40 y
13 10 -1 30 y
14 22 -1 30 y
The process is as follows: Note that groupby is done by TWO columns:
So for each main:
a) Selecting the group that all of the b values is 1. In my data and this df there is only one group with this condition.
b) Selecting first two groups (from top of df) that all of their b values are -1.
Note that there is a possibility in my data that there are no groups that has a or b condition. If that is the case, returning whatever matches the criteria is fine. For example the output could be only one group or no groups at all.
The groups that I want are shown below:
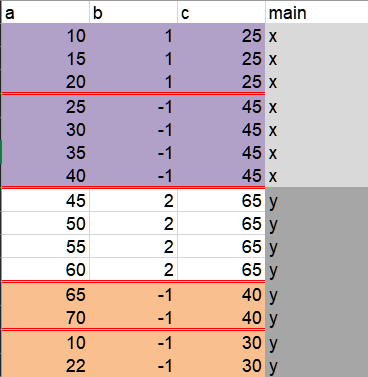
This is my attempt based on this answer but it appears that something else must change:
# identify groups with all 1
m1 = df['b'].eq(1).groupby(df['c', 'main']).transform('all')
# identify groups with all -1
m2 = df['b'].eq(-1).groupby(df['c', 'main']).transform('all')
# keep rows of first 2 groups with all -1
m3 = df[['c', 'main']].isin(df.loc[m2, ['c', 'main']].unique()[:2])
# select m1 OR m3
out = df[m1 | m3]
>Solution :
You can update the previous code to get the first 2 unique "c" per main:
groups = [df['c'], df['main']]
# identify groups with all 1
m1 = df['b'].eq(1).groupby(groups).transform('all')
# identify groups with all -1
m2 = df['b'].eq(-1).groupby(groups).transform('all')
# keep rows of first 2 groups with all -1, per main
keep = set.union(*df.loc[m2, ['c', 'main']].groupby('main')['c']
.agg(lambda x: set(x.unique()[:2])))
# {25}
m3 = df['c'].isin(keep)
# select m1 OR m3
out = df[m1 | m3]
Or using a merge, but this won’t necessarily keep the original order of the rows:
groups = [df['c'], df['main']]
# identify groups with all 1
m1 = df['b'].eq(1).groupby(groups).transform('all')
# identify groups with all -1
m2 = df['b'].eq(-1).groupby(groups).transform('all')
# keep rows of first 2 groups with all -1, per main
ref = df.loc[m2, ['c', 'main']].drop_duplicates().groupby('main').head(2)
out = pd.concat([df[m1], df.merge(ref)], ignore_index=True)
Output:
a b c main
0 10 1 25 x
1 15 1 25 x
2 20 1 25 x
3 25 -1 45 x
4 30 -1 45 x
5 35 -1 45 x
6 40 -1 45 x
11 65 -1 40 y
12 70 -1 40 y
13 10 -1 30 y
14 22 -1 30 y