I have two dataframes like as shown below
tdf = pd.DataFrame({'subj_id': [11,12,13,14,15],
'dash': np.random.choice(list('PPPS'),size=(5)),
'dumeel': np.random.choice(list('QWRR'),size=(5)),
'dumma': np.random.choice((1234),size=(5)),
'target': np.random.choice([0,1],size=(5))
})
cdf = pd.DataFrame({'key_index': [1,1,1,3,3],
'dash': np.random.choice(list('abcd'),size=(5)),
'dumeel': np.random.choice(list('test'),size=(5)),
'dumma': np.random.choice((7890),size=(5))
})
As you can see that cdf contains it’s index (also key) in a column called key_index. However, I have to merge these records with tdf to get the subj_id column.
Basically, key_index = 1 in cdf corresponds to 2nd index row in tdf. key_index = 3 corresponds to 4th index row in tdf etc. key_index + 1 in cdf always corresponds to = matching index position in tdf
I tried the below but it doesn’t work. I don’t know how to add and scale this for million data rows
cdf.merge(tdf, right_index=True, left_index=False) #merge error
cdf.merge(tdf, right_index=False, left_index=True) #merge error
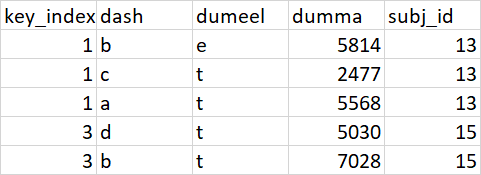
I expect my output to be like as shown below
>Solution :
Don’t merge, use map the single column you want atfer increasing the reference by 1:
cdf['subj_id'] = cdf['key_index'].add(1).map(tdf['subj_id'])
Output:
key_index dash dumeel dumma subj_id
0 1 c e 427 13
1 1 b s 7090 13
2 1 d t 4056 13
3 3 a e 4186 15
4 3 b s 1433 15
Alternative with merge:
cdf.merge(tdf['subj_id'],
left_on=cdf['key_index'].add(1),
right_index=True).drop(columns='key_0')