I am not from web scaping or website/html background and new to this field.
Trying out scraping elements from this link that contains containers/cards.
I have tried below code and find a little success but not sure how to do it properly to get just informative content without getting html/css elements in the results.
from bs4 import BeautifulSoup as bs
import requests
url = 'https://ihgfdelhifair.in/mis/Exhibitors'
page = requests.get(url)
soup = bs(page.text, 'html')
What I am looking to extract (as practice) info from below content:
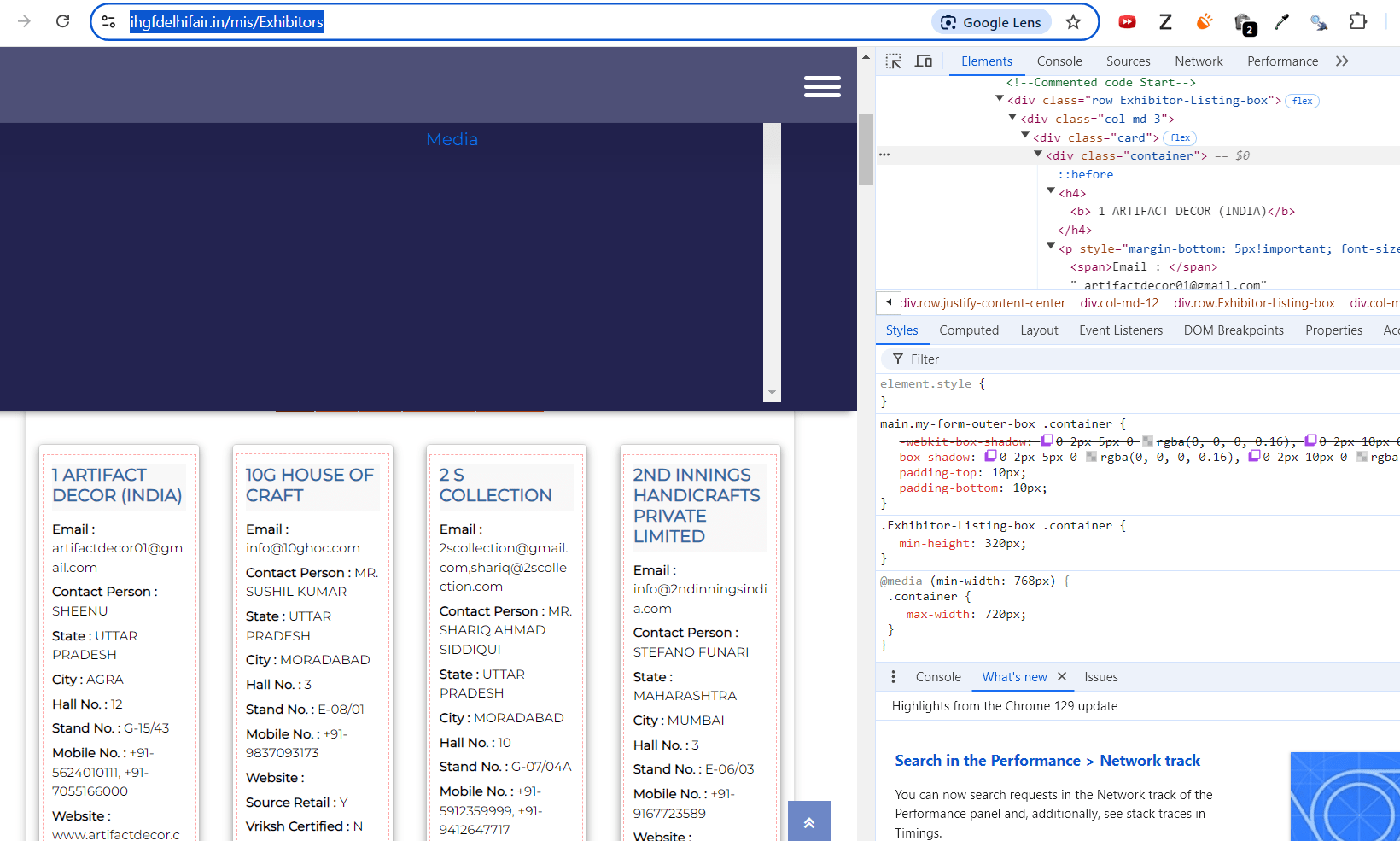
cards = soup.find_all('div', class_="row Exhibitor-Listing-box")
cards
below sort of content it display:
[<div class="row Exhibitor-Listing-box">
<div class="col-md-3">
<div class="card">
<div class="container">
<h4><b> 1 ARTIFACT DECOR (INDIA)</b></h4>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Email : </span> artifactdecor01@gmail.com</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Contact Person : </span> SHEENU</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>State : </span> UTTAR PRADESH</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>City : </span> AGRA</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Hall No. : </span> 12</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Stand No. : </span> G-15/43</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Mobile No. : </span> +91-5624010111, +91-7055166000</p>
<p style="margin-bottom: 5px!important; font-size: 11px;"><span>Website : </span> www.artifactdecor.com</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Source Retail : </span> Y</p>
<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Vriksh Certified : </span> N</p>
</div>
Now when I use below code to extract element:
for element in cards:
title = element.find_all('h4')
email = element.find_all('p')
print(title)
print(email)
Output: It is giving me the info that I need but with html/css content in it which I do not want
[<h4><b> 1 ARTIFACT DECOR (INDIA)</b></h4>, <h4><b> 10G HOUSE OF CRAFT</b></h4>, <h4><b> 2 S COLLECTION</b></h4>, <h4><b> ........]
[<p style="margin-bottom: 5px!important; font-size: 13px;"><span>Email : </span> artifactdecor01@gmail.com</p>, <p style="margin-bottom: 5px!important; font-size: 13px;"><span>Contact Person : </span> ..................]
So how can I take out just title, email, Contact Person, State, City elements from this without html/css in results?
>Solution :
As Manos Kounelakis suggested, what you’re likely looking for is the text attribute of BeautifulSoup HTML elements. Also, it is more natural to split up the html based on the elements with the class card rather than the row elements, as the card elements correspond to each visual card unit on the screen. Here is some code which will print the info fairly nicely:
import requests
from bs4 import BeautifulSoup as bs
url = "https://ihgfdelhifair.in/mis/Exhibitors"
page = requests.get(url)
soup = bs(page.text, features="html5lib")
cards = soup.find_all("div", class_="card")
for element in cards:
title = element.find("h4").text
other_info = [" ".join(elem.text.split()) for elem in element.find_all("p")]
print("Title:", title)
for info in other_info:
print(info)
print("-" * 80)