I am having a csv file , which contains a range of numbers in a column. I also have list of valid range. I need identify the possible range for the matching numbers in csv.
valid_range = ["0-1", "1-2", "0-5", "5-10", "10-15", "15-20", ">20","mixed"]
csv data :
What I have:
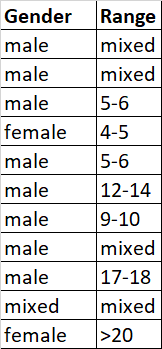
What I need:
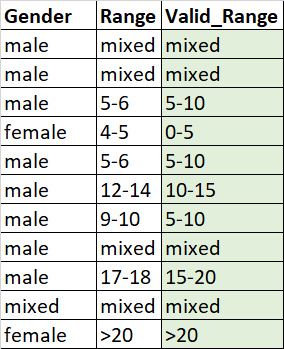
Anything greater than 20 will have ">20" and mixed will have the same.
df = {‘Gender’: {0: ‘male’,
1: ‘male’,
2: ‘male’,
3: ‘female’,
4: ‘male’,
5: ‘male’,
6: ‘male’,
7: ‘male’,
8: ‘male’,
9: ‘mixed’,
10: ‘female’},
‘Range’: {0: ‘mixed’,
1: ‘mixed’,
2: ‘5-6’,
3: ‘4-5’,
4: ‘5-6′,
5: ’12-14’,
6: ‘9-10’,
7: ‘mixed’,
8: ’17-18′,
9: ‘mixed’,
10: ‘>20’}}
>Solution :
If you don’t have overlap, you can rely on the upper bound.
Then use of a bit or regex magic and pandas.cut:
# non overlapping ranges
valid_range = ["0-5", "5-10", "10-15", "15-20", ">20", "mixed"]
# define bins (could also be coded as list directly!)
bins = (pd.Series(valid_range[:-2]).str.extract('(\d+)$', expand=False)
.astype(int).to_list()
)
bins = [0]+bins+[float('inf')]
# [0, 5, 10, 15, 20, inf]
df['Valid_Range'] = ( # replace ">x" with upper bound + 1
pd.cut(df['Range'].str.replace('>.*', f'{bins[-1]+1}', regex=True)
# extract trailing digits
.str.extract('(\d+)$', expand=False).astype(float),
bins=bins, labels=valid_range[:-1])
.values.add_categories(valid_range[-1]) # cut output is Categorical
.fillna(valid_range[-1]) # fill nans that correspond to initial "mixed"
)
output:
Gender Range Valid_Range
0 male mixed mixed
1 male mixed mixed
2 male 5-6 5-10
3 female 4-5 0-5
4 male 5-6 5-10
5 male 12-14 10-15
6 male 9-10 5-10
7 male mixed mixed
8 male 17-18 15-20
9 mixed mixed mixed
10 female >20 >20