data = [[1, 2.4, 3, np.nan], [4, 5.3, 6, np.nan], [np.nan, 8, 3, np.nan]] # Example data
output_data = pd.DataFrame(data, columns=['total', 'count1', 'count2', 'count3'])
output_data
total count1 count2 count3
0 1.0 2.4 3 NaN
1 4.0 5.3 6 NaN
2 NaN 8.0 3 NaN
# grab all columns to format
all_cols = ['total', 'count1', 'count2', 'count3', 'count4']
float_cols = ['total'] # dont want to convert these to integer
# add empty cols if they do not exist, and format columns correctly
for col in all_cols:
# add empty col if it didnt exist
if not (col in output_data.columns):
output_data[col] = ''
# else convert to integer-string with NA --> ''
else:
is_row_all_nulls = sum(output_data[col].isnull()) == output_data.shape[0]
if is_row_all_nulls:
output_data[col] = output_data[col].fillna(value = '')
else:
if (col in float_cols):
output_data[col] = output_data[col].fillna('').astype(str)
else:
output_data[col] = output_data[col].fillna('').astype(str).str.split('.').str[0]
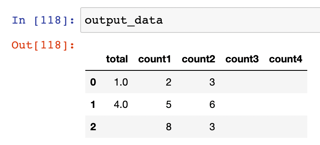
This code gives us exactly the output that we want. Columns with all NaN values get converted to empty strings. Not shown, but missing columns would be created and filled with empty strings. All columns are converted to strings, and NAN values are replaced with empty strings. The total column displays as a float within a string, whereas the other columns display as an integer within the string by chopping off everything after the decimal place via str.split('.').str[0].
However, this triple-nested if else solution feels very messy. We would prefer to remove the nested if else with a cleaner, less-nested, more sophisticated solution. How could we achieve this?
Edit: updated with count4 added to all_cols
>Solution :
One option using fillna, astype, and mask:
types = {c: int for c in all_cols}
for c in float_cols:
types[c] = float
# or
# types = {'total': float, 'count1': int, 'count2': int, 'count3': int}
output_data = output_data.fillna(0).astype(types).mask(output_data.isna(), '')
Output:
total count1 count2 count3
0 1.0 2 3
1 4.0 5 6
2 8 3