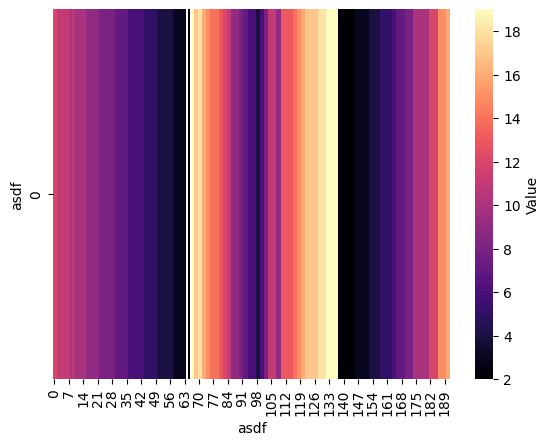
Using seaborn i am generating heatmaps for various series of a DataFrame.
The main code that I use is the following:
def plot_heatmap(data, cmap, x_label, y_label, y_ticks = None):
fig, ax = plt.subplots()
heatmap = sns.heatmap([data], robust=True,cmap=cmap, annot=False, cbar_kws={"label": "Value"}, ax=ax)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
if y_ticks:
heatmap.set_yticklabels([y_ticks])
plt.show()
And it’s invoked per case that I have (for each Pandas.Series). My issue is that the generated result looks like this:
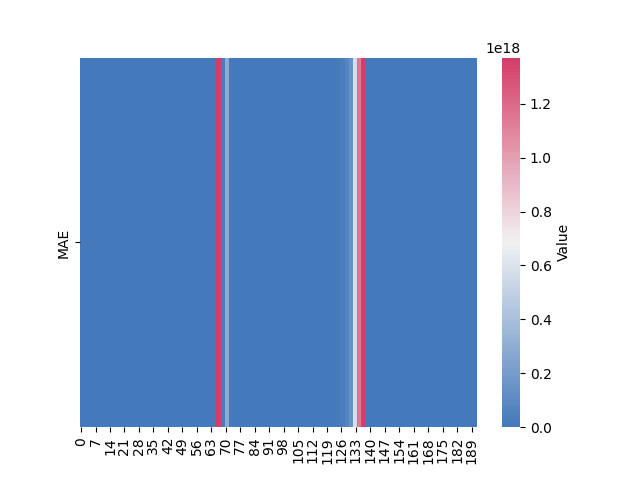
But the thing is, that this looks somewhat deceiving. I generated the following random dataset for this plot: gist for dataset.
The number of zeroes as you see is 1. But someone, observing this plot would think otherwise.
So, how could I improve this plot to make it more accurate? I tried various cmaps like:
cmap = sns.diverging_palette(220, 10, as_cmap=True)
cmap2 = sns.diverging_palette(250, 0, sep=1, n=256, as_cmap=True)
cmap3 = 'gist_rainbow'
...
But I didn’t quite get the desired result. Thank you in advance!
>Solution :
You have a massive range of scales. You can try plotting a logarithm of the data:
plot_heatmap(np.log10(df.data), cmap="plasma", x_label="asdf", y_label="asdf")
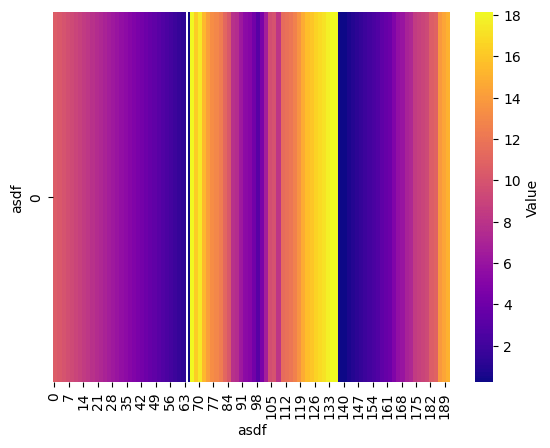
And/or create categories from the data:
bins = np.logspace(np.log10(0.1), np.log10(df["data"].max()), 20)
labels = np.arange(1, len(bins))
df['binned'] = pd.cut(df['data'], bins=bins, labels=labels)
plot_heatmap(df["binned"], cmap="magma", x_label="asdf", y_label="asdf")