I have a csv file which looks liks this:
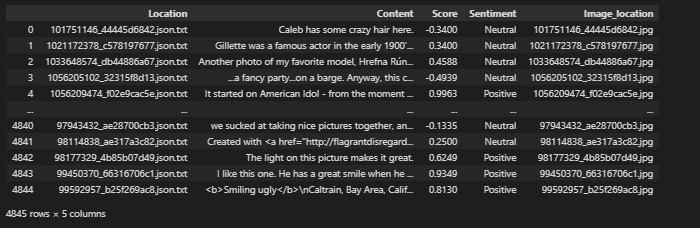
I want to load the image (from df['Image_location']) and text (from df['Content']) together, so I did the following operations:
df = pd.read_csv(csv_data_dir, encoding= 'cp1252')
features = df[['Content', 'Image_location']]
labels = df['Sentiment']
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
def process_path(x):
content, image_path = x[0], x[1]
print(image_path)
img = tf.io.read_file(image_path)
img = tf.io.decode_jpeg(img, channels=3)
return content, img
dataset = dataset.map(lambda x, y: (process_path(x), y))
dataset = dataset.batch(32, drop_remainder = True)
Upon running the training loop:
for step , (x, y) in enumerate(dataset):
print(f"Step:{step}")
InvalidArgumentError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_19112/3450653832.py in <module>
1 import matplotlib.pyplot as plt
----> 2 for step , (x, y) in enumerate(dataset):
3 print(f"Step:{step}")
4 content = x[0]
5 image = x[1]
~\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\data\ops\iterator_ops.py in __next__(self)
798 def __next__(self):
799 try:
--> 800 return self._next_internal()
801 except errors.OutOfRangeError:
802 raise StopIteration
~\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\data\ops\iterator_ops.py in _next_internal(self)
781 # to communicate that there is no more data to iterate over.
782 with context.execution_mode(context.SYNC):
--> 783 ret = gen_dataset_ops.iterator_get_next(
784 self._iterator_resource,
785 output_types=self._flat_output_types,
~\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\gen_dataset_ops.py in iterator_get_next(iterator, output_types, output_shapes, name)
2842 return _result
2843 except _core._NotOkStatusException as e:
-> 2844 _ops.raise_from_not_ok_status(e, name)
2845 except _core._FallbackException:
2846 pass
~\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\framework\ops.py in raise_from_not_ok_status(e, name)
7105 def raise_from_not_ok_status(e, name):
7106 e.message += (" name: " + name if name is not None else "")
-> 7107 raise core._status_to_exception(e) from None # pylint: disable=protected-access
7108
7109
InvalidArgumentError: Cannot add tensor to the batch: number of elements does not match. Shapes are: [tensor]: [344,500,3], [batch]: [500,333,3] [Op:IteratorGetNext]
Any idea where I’m going wrong or how to batch this dataset properly as without dataset = dataset.batch(32, drop_remainder = True), the code works fine.
>Solution :
I can imagine that not all images have the same shape and that is why you are getting mismatches when batch_size > 1. I would recommend resizing all images to the same size. Here is an example:
def process_path(x):
content, image_path = x[0], x[1]
img = tf.io.read_file(image_path)
img = tf.io.decode_png(img, channels=3)
img = tf.image.resize(img,[120, 120], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return content, img
Otherwise, you will have to sort your batches by image size.