Is there a way blank out the repetitive customer ids, and just leave the first ones for each customer?
declare @orderTable table (
customerid int,
orderAmt decimal(18,4)
)
insert @orderTable
values
(1,10),
(1,20),
(1,20),
(1,20),
(3,10),
(3,15),
(3,30),
(3,10)
select * from @orderTable
order by customerid
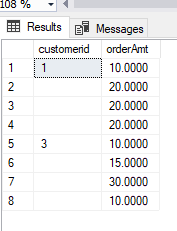
Expected outpu:
customerid orderAmt
1 10.0000
20.0000
20.0000
20.0000
3 10.0000
15.0000
30.0000
10.0000
>Solution :
Really belongs in the presentation layer. That said, you would also need a proper sequence to maintain an explicit order.
You may want to replace ... order by (Select null) ... with ... order by SomeCol ...
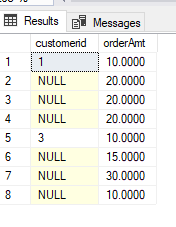
select customerid = case when row_number() over (partition by Customerid order by (Select null)) = 1 then customerid end
,orderAmt
From @orderTable O
order by O.customerid
Results
EDIT – If You DON’T WANT NULL
select customerid = concat('',case when row_number() over (partition by Customerid order by (Select null)) = 1 then customerid end)
,orderAmt
From @orderTable O