I have 2 issues relating to the response result from OpenAI completion.
The following result doesn’t return back the full text when I give a content of 500 word and prompt "Fix grammar mistakes" (Is tokens issue?)
The second issue is when the text sometimes have some double quotes OR single quotes it messes with the JSON format So I delete any type of quotes from the content (not sure if it’s the best solution but I may prefer done it on JS not PHP)
curl_setopt($ch, CURLOPT_POSTFIELDS, "{\n \"model\": \"text-davinci-001\",\n \"prompt\": \"" . $open_ai_prompt . ":nn" . $content_text . "\",\n \"temperature\": 0,\n \"top_p\": 1.0,\n \"frequency_penalty\": 0.0,\n \"presence_penalty\": 0.0\n}");
"message": "We could not parse the JSON body of your request. (HINT:
This likely means you aren’t using your HTTP library correctly. The
OpenAI API expects a JSON payload, but what was sent was not valid
JSON.
>Solution :
Regarding token limits
As stated on official OpenAI website:
Depending on the model used, requests can use up to
4097tokens shared
between prompt and completion. If your prompt is4000tokens, your
completion can be97tokens at most.The limit is currently a technical limitation, but there are often
creative ways to solve problems within the limit, e.g. condensing your
prompt, breaking the text into smaller pieces, etc.
Switch text-davinci-001 for a GPT-3 model because the token limits are higher.
GPT-3 models:

I think you don’t understand how tokens work: 500 words is more than 500 tokens. Use Tokenizer to calculate the number of tokens.
Regarding double quotes in JSON
You can escape double quotes in JSON by using \ in front of double quotes like this:
"This is how you can escape \"double quotes\" in JSON."
But… This is more of a quick fix. For proper solution, see @ADyson’s comment above:
Don’t build your JSON by hand like that. Make a PHP object / array
with the correct structure, and then usejson_encode()to turn it into
valid JSON, it will automatically handle any escaping etc which is
needed, and you can also use the options to tweak certain things about
the output – check the PHP documentation.
EDIT 1
You need to set the max_tokens parameter higher. Otherwise, the output will be shorter than your input. You will not get the whole fixed text back, but just a part of it.
EDIT 2
Now you set the max_tokens parameter too high! If you set max_tokens = 5000, this is too much even for the most capable GPT-3 model (i.e., text-davinci-003). The prompt and the completion together can be 4097 tokens.
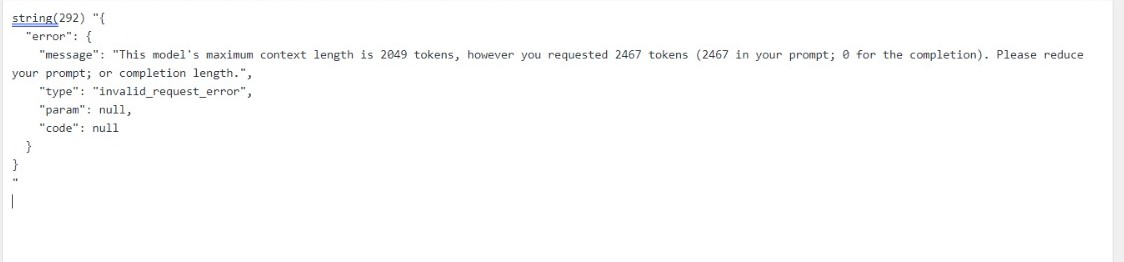
You can figure this out if you take a look at the error you got:
"error": {"message": "This model's maximum context length is 4097 tokens, however you requested 6450 tokens (1450 in your prompt; 5000 for the completion). Please reduce your prompt; or completion length."}