I have the following string in a column within a row in a pandas dataframe. You could just treat it as a string.
;2;613;12;1;Ajc hw EEE;13;.387639;1;EXP;13;2;128;12;1;NNN XX Ajc;13;.208966;1;SGX;13;..
It goes on like that.
I want to convert it into a table and use the semi colon ; symbol as a delimiter. The problem is there is no new line delimiter and I have to estimate it to be every 10 items.
So, it should look something like this.
;2;613;12;1;Ajc hw EEE;13;.387639;1;EXP;13;
2;128;12;1;NNN XX Ajc;13;.208966;1;SGX;13;..
How do I convert that string into a new dataframe in pandas. After every 10 semi colon delimiters, a new row should be created.
I have no idea how to do this, any help would be greatly appreciated in terms of tools or ideas.
>Solution :
This should work
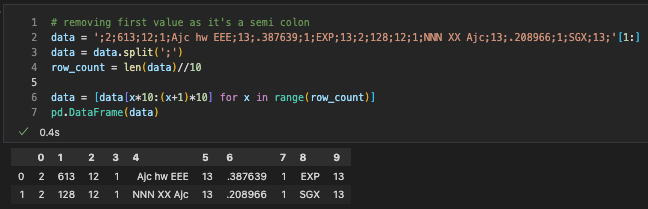
# removing first value as it's a semi colon
data = ';2;613;12;1;Ajc hw EEE;13;.387639;1;EXP;13;2;128;12;1;NNN XX Ajc;13;.208966;1;SGX;13;'[1:]
data = data.split(';')
row_count = len(data)//10
data = [data[x*10:(x+1)*10] for x in range(row_count)]
pd.DataFrame(data)
I used a double slash for dividing but as your data length should be dividable by 10, you can use only one.
Here’s a screenshot of my output.