I have a python dataframe df_A which index column contains integer data and represent a time stamp in seconds time row (it might be not have a strictly monotonic gradient).
And I have another dataframe df_B which only contains one set of data. One of its "cells" give me a start time.
My goal is to take this start time from df_B, put it in the first row of a new column to be created in df_A and start a calculation from there based on the index row.
The index column of df_A is integer numbers like that:
Int64Index([ 2374, 2376, 2377, 2378, 2379, 2380, 2381, 2383, 2384,
2385,
...
10531, 10532, 10533, 10535, 10536, 10537, 10538, 10539, 10540,
10541],
dtype='int64', name='TimePeak', length=7107)
df_B looks like that:
df_B = pd.DataFrame([['2021-07-08T08:56:46.637', 590, 0, 4270.29]], columns=['BeginTime', 'Altitude', 'Status', 'Duration'])
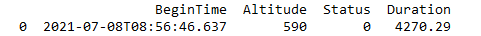
First I get my starting time value by df_B:
For further calculations I need the string type entry "BeginTime" to be compatible with integers from df_B.index. That’s why I convert everything into datetime format:
# Gain the first entry of the new dataframe column 'time'
df_A['time'].iloc[0] = pd.to_datetime(df_B.BeginTime)
But the first entry is not put into the first row of the new column as it produces a ValueError: Could not convert object to NumPy datetime
I do not understand why it’s not converted. Do I have to define its contents more specifically? Other datetime values of this format are converted without any error message to the format YYYY-MM-DD hh:mm:ss.sss (without the "T" inbetween)
Then I would calculate the delta time:
# calculate timedelta according to the index column values starting in the second
# row as the first row has no reference to be calculated from
for i in range(1, len(df_A)):
df_A['deltaT'][i] = df_A.index[i] - df_A.index[i-1]
This gives me a key error for deltaT. Why?
I can define an empty column first:
df_A['deltaT'] = pd.to_timedelta(pd.Series(dtype='float'), unit='s')
for i in range(1, len(df_A)):
df_A['deltaT'][i] = df_A.index[i] - df_A.index[i-1]
But this would end in a row of warnings:
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_A['deltaT'][i] = df_A.index[i] - df_A.index[i-1]
Which I could suppress with:
pd.options.mode.chained_assignment = None but I think the main problem is located somewhere above in the code… (?)
After I would calculate the further rows based on the difference deltaT by two rows in a row:
# calculate the further rows
for i in range (1, len(df_A)):
df_A[i,'time'] = df_A.iloc[i-1]['time'] + pd.to_timedelta(df_A.iloc[i]['deltaT'](1, unit='s'))
df_A['time']
But this calculation won’t be either performed.
The complete code:
import pandas as pd
import numpy as np
# df_B:
df_B = pd.DataFrame([['2021-07-08T08:56:46.637', 590, 0, 4270.29]], columns=['BeginTime', 'Altitude', 'Status', 'Duration'])
# df_A
df_A = pd.DataFrame([[2374, 4.5],[2376, 5.7],[2377,23.0],[2378,9.2],[2379,18.7],[2380,10.4],[2381,12.2],[2383,23.9],[2384,21.6],
[2385, 12.1]], columns=['TimePeak', 'data'])
df_A.set_index('TimePeak') # indeed, the index is set earlier due to a merge of several *.csv files
# Gain the first entry of the new dataframe column 'time' and convert it to timedate format
df_A['time'].iloc[0] = pd.to_datetime(df_B.BeginTime)
# calculate timedelta according to the index column values starting in the second
# row as the first row has no reference to be calculated from
for i in range(1, len(df_A)):
df_A['deltaT'][i] = df_A.index[i] - df_A.index[i-1]
# calculate the further rows
for i in range (1, len(df_A)):
df_A[i,'time'] = df_A.iloc[i-1]['time'] + pd.to_timedelta(df_A.iloc[i]['deltaT'](1, unit='s'))
df_A['time']
I also tried to reset the index but it neither worked.
Any hints for me to understand where I was mislead?
The final output should look like this:

>Solution :
The exact logic is unclear, but you almost certainly don’t need a loop.
If I understand correctly, you want to start the time with the value from df_B then increment 1s for each row. Then use date_range:
df_A['time'] = pd.date_range(df_B.loc[0, 'BeginTime'], periods=len(df_A), freq='s')
Or, closer to your original approach, if you want to use the index as reference:
df_A['time'] = (pd.Timestamp(df_B.loc[0, 'BeginTime'])
+pd.TimedeltaIndex(df_A.index-df_A.index[0], unit='s')
)
Output:
TimePeak data time
0 2374 4.5 2021-07-08 08:56:46.637
1 2376 5.7 2021-07-08 08:56:47.637
2 2377 23.0 2021-07-08 08:56:48.637
3 2378 9.2 2021-07-08 08:56:49.637
4 2379 18.7 2021-07-08 08:56:50.637
5 2380 10.4 2021-07-08 08:56:51.637
6 2381 12.2 2021-07-08 08:56:52.637
7 2383 23.9 2021-07-08 08:56:53.637
8 2384 21.6 2021-07-08 08:56:54.637
9 2385 12.1 2021-07-08 08:56:55.637