I have a Input dataframe:
import pandas as pd
# Define the input data
data = {
'ID': [500, 200, 300],
'A': [3, 3, ''],
'B': [3, 1, ''],
'C': [2, '' ,''],
'D': ['', 2, 1],
'E': ['', '',2 ],
}
# Convert the input data to a Pandas DataFrame
df = pd.DataFrame(data)
Input table
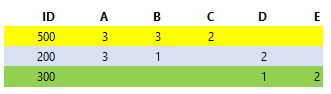
I need to transform this input as you can see in below output example:
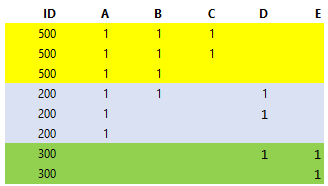
If you have any ideas please share. Thank you very much!
>Solution :
You can repeat the rows using the max number per row, then compare to a groupby.cumcount to map the 1/'':
tmp = df.set_index('ID').apply(pd.to_numeric, errors='coerce')
out = (
tmp.loc[tmp.index.repeat(tmp.max(axis=1))]
.pipe(lambda d: d.gt(d.groupby(level='ID').cumcount(), axis=0))
.replace({True: 1, False: ''})
.reset_index()
)
NB. you can simplify the code if you use NaN in place of empty strings.
Output:
ID A B C D E
0 500 1 1 1
1 500 1 1 1
2 500 1 1
3 200 1 1 1
4 200 1 1
5 200 1
6 300 1 1
7 300 1