I currently have a Dataframe that looks something like this:
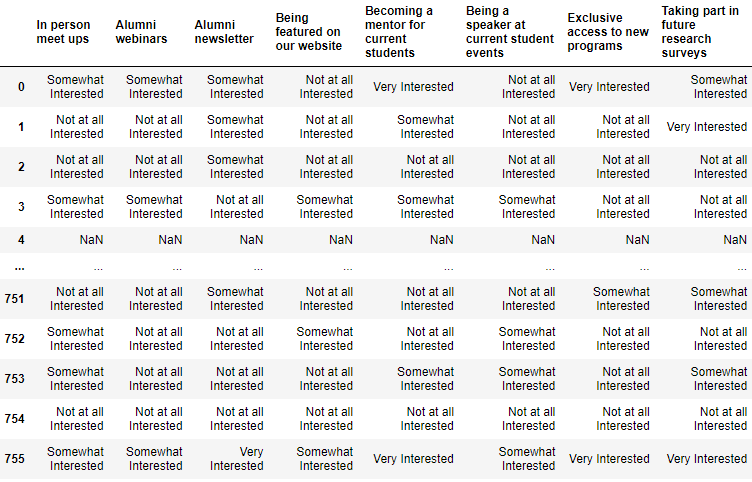
The unique values are [‘Somewhat Interested’, ‘Not at all Interested’, nan,’Very Interested’]
How would I go about creating a new dataframe that would have the same columns as above
but for the index values ‘Somewhat Interested’, ‘Not at all Interested’, nan,’Very Interested’ and the values inside the cell are the counts of each type of response. Im thinking a pivot table might do the trick but Im not sure.
What I want
| In person meet ups | alumni webinars | alumni webinars | etc… | |
|---|---|---|---|---|
| Some what interested | 24 | 32 | 12 | |
| Not interested | 32 | 42 | 4 | |
| very intersted | 21 | 31 | 53 |
>Solution :
Combine value_counts with apply to do it per column:
df.apply(pd.value_counts)