I have a data as shown below:
qty_min qty_max region_min region_max subj region
11 1 10 10 ab UK
21 1 nan 20 ab UK
nan nan nan 30 ab UK
nan 2 nan 34 bc US
nan 2 20 nan bc US
10 nan nan nan bc TZ
11 nan nan 47 de TZ
13 3 109 31 de TZ
df = pd.read_clipboard()
print(df)
I would like to fillna() in each of the columns: qty_min, qty_max, region_min, region_max based on a pattern.
For example: If there is NaN in qty_min and qty_max columns, we need to fillna() using groupby of subj and ffill().bfill().
Similarly, if there is NaN in region_max, region_min, we need to fillna() using groupby of region and ffill().bfill()
So, I tried the below:
df['qty_min'] = df.groupby(['subj'], sort=False)['qty_min'].apply(lambda x: x.ffill().bfill())
df['qty_max'] = df.groupby(['subj'], sort=False)['qty_max'].apply(lambda x: x.ffill().bfill())
df['region_min'] = df.groupby(['region'], sort=False)['region_min'].apply(lambda x: x.ffill().bfill())
df['region_max'] = df.groupby(['region'], sort=False)['region_max'].apply(lambda x: x.ffill().bfill())
As you can see that this is not elegant. Moreover, I have 20 plus columns like this in real data which I would like to fill using the same way (groupby column and ffill.bfill())
I have created a dict like below manually to identify the corresponding groupby column for filling NaN.
I’m open to modifying the way we store this info. You can use whatever data structure is easy.
fillna_dict= {
"subj": ['qty_min','qty_max'],
"region": ['region_min','region_max']
}
Is there any elegant and efficient approach to do this?
I expect my output to be like the below:
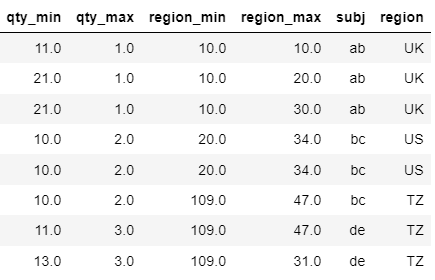
>Solution :
As you have separate conditions you need to have several lines.
What you would do is to refactor the code to reuse the groups and a single function:
f = lambda x: x.ffill().bfill()
g1 = df.groupby(['subj'], sort=False)
g2 = df.groupby(['region'], sort=False)
df['qty_min'] = g1['qty_min'].apply(f)
df['qty_max'] = g1['qty_max'].apply(f)
df['region_min'] = g2['region_min'].apply(f)
df['region_max'] = g2['region_max'].apply(f)
Using your dictionary:
f = lambda x: x.ffill().bfill()
fillna_dict= {
"subj": ['qty_min','qty_max'],
"region": ['region_min','region_max']
}
for k, cols in fillna_dict.items():
df[cols] = df.groupby(df[k])[cols].apply(f)
output:
qty_min qty_max region_min region_max subj region
0 11.0 1.0 10.0 10.0 ab UK
1 21.0 1.0 10.0 20.0 ab UK
2 21.0 1.0 10.0 30.0 ab UK
3 10.0 2.0 20.0 34.0 bc US
4 10.0 2.0 20.0 34.0 bc US
5 10.0 2.0 109.0 47.0 bc TZ
6 11.0 3.0 109.0 47.0 de TZ
7 13.0 3.0 109.0 31.0 de TZ