I have a dataframe like as shown below
df=pd.DataFrame({'subjects':['A','A','D','B','B','C'],
'B':['12','12','13','14','14','16'],
'C':[21,23,24,25,26,27]
})
df['r_no'] = df.groupby(['subjects','B']).cumcount()+1
Now, I would like to only select rows that had only r_no = 1 (and not r_no > 1).
I tried the below
df[df['subjects'].value_counts() == 1]
df.iloc[df['subjects'].value_counts() == 1:,]
df.ix[df['subjects'].value_counts() == 1:,]
df[(df['r_no'] == 1) & (df['r_no'] < 2)]
None of them worked.
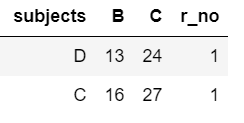
I expect my output to be like as shown below.
You can see that subjects = A and subjects = B is excluded because they also had rows where r_no > 1. Basically, I want to select subjects that had only one record for them (r_no) in dataframe
>Solution :
IIUC, what you want to do it just to keep the groups of size 1:
df[df.groupby(['subjects','B'])['C'].transform(len).le(1)]
Or maybe even just keeping the subjects with unique rows:
df[~df['subjects'].duplicated(keep=False)]
output:
subjects B C
2 D 13 24
5 C 16 27