I have a dataframe like as below
df = pd.DataFrame(
{'stud_id' : [101, 101, 101, 101,
101, 101, 101, 101],
'sub_code' : ['CSE01', 'CSE02', 'CSE03',
'CSE06', 'CSE05', 'CSE04',
'CSE07', 'CSE08'],
'marks' : ['A','B','C','D',
'E','F','G','H']}
)
I would like to do the below
a) Filter my dataframe based on sub_code using a list of values
b) For the filtered/selected rows, replace their marks value by a constant value – FAIL
So, I tried the below but it doesn’t work and results in NA for non-filtered rows. Instead of NA, I would like to see the actual value
sub_list = ['CSE01', 'CSE02', 'CSE03','CSE06', 'CSE05', 'CSE04']
df['marks'] = df[df['sub_code'].isin(sub_list)]['marks'].replace(r'^([A-Za-z])*$','FAIL', regex=True)
I expect my output to be like as below
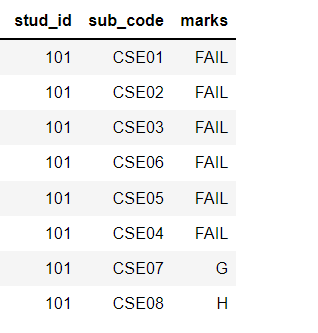
>Solution :
You can use pandas.loc
Code:
df.loc[df["sub_code"].isin(sub_list), "marks"] = "FAIL"
Output:
stud_id sub_code marks
101 CSE01 FAIL
101 CSE02 FAIL
101 CSE03 FAIL
101 CSE06 FAIL
101 CSE05 FAIL
101 CSE04 FAIL
101 CSE07 G
101 CSE08 H