I have a dataframe like below:
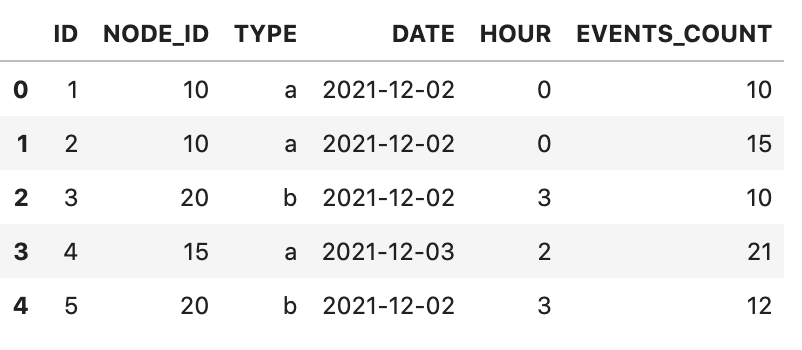
data = {'ID': [1,2,3,4,5],
'NODE_ID': [10,10,20,15,20],
'TYPE': ['a','a','b','a','b'],
'DATE': ['2021-12-02','2021-12-02','2021-12-02','2021-12-03','2021-12-02'],
'HOUR': [0,0,3,2,3],
'EVENTS_COUNT': [10,15,10,21,12]
}
df = pd.DataFrame(data,columns=['ID','NODE_ID', 'TYPE', 'DATE', 'HOUR', 'EVENTS_COUNT'])
I have two different TYPE – a and b. I want to create a dataframe out of this so I have a sum of each TYPE (a and b) for the group of NODE_ID, DATE, HOUR.
The expected output is
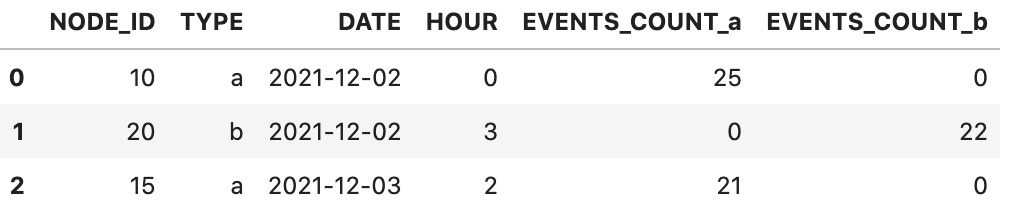
Can you please suggest how to do this?
EDIT:
Updated the expected output.
>Solution :
Try with pivot_table:
output = (df.pivot_table("EVENTS_COUNT",["NODE_ID","DATE","HOUR"],"TYPE","sum")
.fillna(0)
.add_prefix("EVENTS_COUNT_")
.reset_index()
.rename_axis(None, axis=1))
>>> output
TYPE NODE_ID DATE HOUR EVENTS_COUNT_a EVENTS_COUNT_b
0 10 2021-12-02 0 25.0 0.0
1 15 2021-12-03 2 21.0 0.0
2 20 2021-12-02 3 0.0 22.0
If there is only one TYPE for each combination of ["NODE_ID", "DATE", "HOUR"], and you would like this as a separate column, you can do:
output["TYPE"] = output.filter(like="EVENTS_COUNT_").idxmax(axis=1).str.lstrip("EVENTS_COUNT_")
>>> output
NODE_ID DATE HOUR EVENTS_COUNT_a EVENTS_COUNT_b TYPE
0 10 2021-12-02 0 25.0 0.0 a
1 15 2021-12-03 2 21.0 0.0 a
2 20 2021-12-02 3 0.0 22.0 b