Desired outcome
I have a table of data that looks like this:
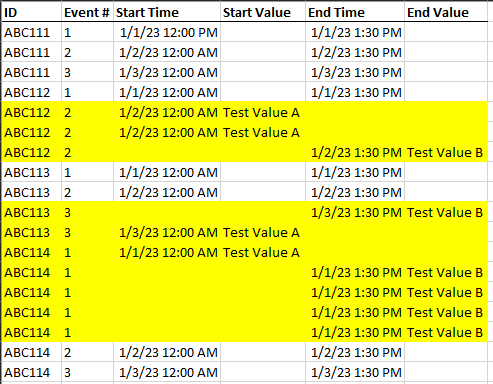
And I want to transform that table to look like this:
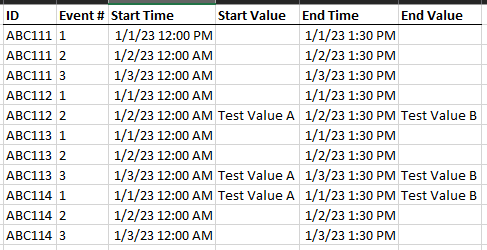
Problem description
The ID and Event# fields are a compound key that represents one unique entry in the table.
Entries can be duplicated two or more times. But some of the row values are distributed among the duplicates. And I don’t always know whether those row values are found in the "first", "last", or some "middle" duplicate.
I want to remove the duplicate entries, while keeping all the populated row values, regardless of where they’re distributed amongst the duplicates.
How can I do this with Pandas?
Looking at some SO posts I think I need to use groupby and fillna or ffill/bfill. But I’m new to Pandas and don’t understand how I can make that work under these conditions:
- Rows are distinguished with a compound key
- There are instances where there’s more than 1 duplicate row
- There’s valid data in more than 1 field distributed across those duplicates
- I don’t always know if the valid row data is located in the "first", "last", or some "middle" duplicate
Here’s the dataframe:
df = pd.DataFrame([['ABC111', 1, '1/1/23 12:00:00', None, '1/1/23 13:30:00', None],
['ABC111', 2, '1/2/23 00:00:00', None, '1/2/23 13:30:00', None],
['ABC111', 3, '1/3/23 00:00:00', None, '1/3/23 13:30:00', None],
['ABC112', 1, '1/1/23 00:00:00', None, '1/1/23 13:30:00', None],
['ABC112', 2, '1/2/23 00:00:00', 'Test Value A', None, None],
['ABC112', 2, '1/2/23 00:00:00', 'Test Value A', None, None],
['ABC112', 2, None, None, '1/2/23 13:30:00', 'Test Value B'],
['ABC113', 1, '1/1/23 00:00:00', None, '1/1/23 13:30:00', None],
['ABC113', 2, '1/2/23 00:00:00', None, '1/2/23 13:30:00', None],
['ABC113', 3, None, None, '1/3/23 13:30:00', 'Test Value B'],
['ABC113', 3, '1/3/23 00:00:00', 'Test Value A', None, None],
['ABC114', 1, '1/1/23 00:00:00', 'Test Value A', None, None],
['ABC114', 1, None, None, '1/1/23 13:30:00', 'Test Value B'],
['ABC114', 1, None, None, '1/1/23 13:30:00', 'Test Value B'],
['ABC114', 1, None, None, '1/1/23 13:30:00', 'Test Value B'],
['ABC114', 1, None, None, '1/1/23 13:30:00', 'Test Value B'],
['ABC114', 2, '1/2/23 00:00:00', None, '1/2/23 13:30:00', None],
['ABC114', 3, '1/3/23 00:00:00', None, '1/3/23 13:30:00', None]],
columns=['ID', 'Event #', 'Start Date', 'Start Value', 'End Date', 'End Value'])
This SO post is the closest potential solution I could find: Pandas: filling missing values by mean in each group
>Solution :
It looks like you want a groupby.first:
out = df.groupby(['ID', 'Event #'], as_index=False).first()
Output:
ID Event # Start Date Start Value End Date End Value
0 ABC111 1 1/1/23 12:00:00 None 1/1/23 13:30:00 None
1 ABC111 2 1/2/23 00:00:00 None 1/2/23 13:30:00 None
2 ABC111 3 1/3/23 00:00:00 None 1/3/23 13:30:00 None
3 ABC112 1 1/1/23 00:00:00 None 1/1/23 13:30:00 None
4 ABC112 2 1/2/23 00:00:00 Test Value A 1/2/23 13:30:00 Test Value B
5 ABC113 1 1/1/23 00:00:00 None 1/1/23 13:30:00 None
6 ABC113 2 1/2/23 00:00:00 None 1/2/23 13:30:00 None
7 ABC113 3 1/3/23 00:00:00 Test Value A 1/3/23 13:30:00 Test Value B
8 ABC114 1 1/1/23 00:00:00 Test Value A 1/1/23 13:30:00 Test Value B
9 ABC114 2 1/2/23 00:00:00 None 1/2/23 13:30:00 None
10 ABC114 3 1/3/23 00:00:00 None 1/3/23 13:30:00 None