I have the following dataframe:
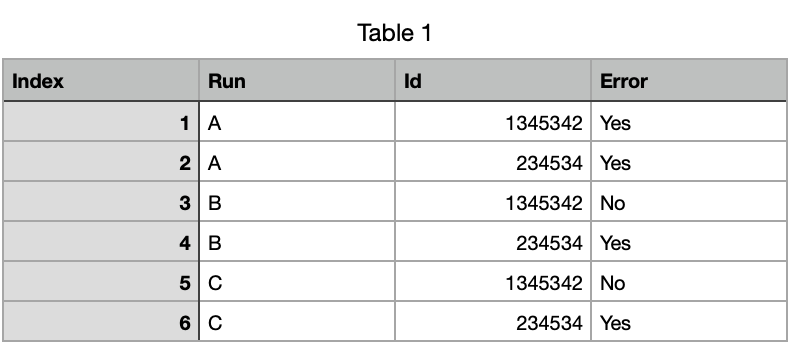
I want to find intersections based on ID that consistently have errors in all the Run.
So, all IDs are repeating in all Runs. I tried to group data by Run first, then as per this similar question. I tried the code, but it doesn’t return an intersection.
filter=all_data_df.groupby('Run')['Error'].transform('nunique') == all_data_df['Error'].nunique()
df = all_data_df.loc[filter]
The results is same dataframe I started with.
How can this be fixed?
I am expecting to obtain
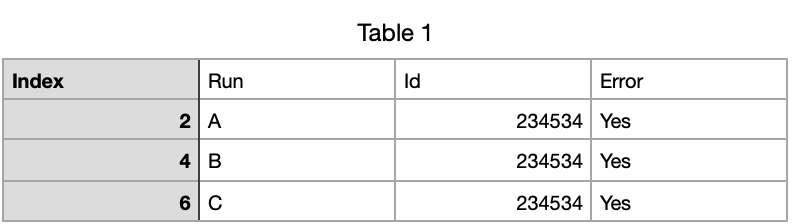
Where only ID 234534 consistently has errors.
>Solution :
You can use boolean indexing to keep only the Ids that have errors in all runs :
# Below, I'm using `df` instead of `all_data_df`
consistent_errors = df["Error"].eq("Yes").groupby(df["Id"]).transform("all")
out = df.loc[consistent_errors]