I have two dataframes df and tf like as given below
df = [{"unique_key": 1, "test_ids": "1.0,15,2.0,nan"}, {"unique_key": 2, "test_ids": "51,75.0,11.0,NaN"},{"unique_key": 3, "test_ids":np.nan},
{"unique_key": 4, "test_ids":np.nan}]
df = pd.DataFrame(df)
test_ids,status,revenue,cnt_days
1,passed,234.54,3
2,passed,543.21,5
11,failed,21.3,4
15,failed,2098.21,6
51,passed,232,21
75,failed,123.87,32
tf = pd.read_clipboard(sep=',')
I would like to link the unique_key column from df to the tf dataframe
For ex: I will show my output below (that’s easy to understand than text)
I was trying something like below
for b in df.test_ids.tolist():
for a in b.split(','):
if a >= 0: # to exclude NA values from checking
for i in len(test_ids):
if int(a) == tf['test_ids'][i]:
tf['unique_key'] = df['unique_key']
But this is neither efficient nor elegant to solve my problem.
Is there any other better way to achieve the expected output shown below?
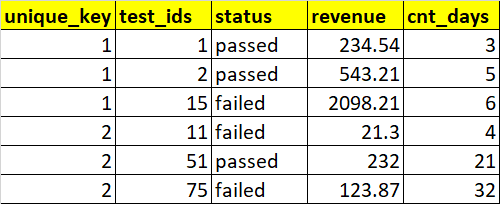
>Solution :
You can create Series with remove duplicates and missing values, swap to dictioanry and for new first column use DataFrame.insert with Series.map:
s = (df.set_index('unique_key')['test_ids']
.str.split(',')
.explode()
.astype(float)
.dropna()
.astype(int)
.drop_duplicates()
d = {v: k for k, v in s.items()}
print (d)
{1: 1, 15: 1, 2: 1, 51: 2, 75: 2, 11: 2}
tf.insert(0, 'unique_key', tf['test_ids'].map(d))
print (tf)
unique_key test_ids status revenue cnt_days
0 1 1 passed 234.54 3
1 1 2 passed 543.21 5
2 2 11 failed 21.30 4
3 1 15 failed 2098.21 6
4 2 51 passed 232.00 21
5 2 75 failed 123.87 32
Another idea is working with DataFrame and create Series for mapping:
s = (df.assign(new = df['test_ids'].str.split(','))
.explode('new')
.astype({'new':float})
.dropna(subset=['new'])
.astype({'new':int})
.drop_duplicates(subset=['new'])
.set_index('new')['unique_key'])
print (s)
new
1 1
15 1
2 1
51 2
75 2
11 2
Name: unique_key, dtype: int64
tf.insert(0, 'unique_key', tf['test_ids'].map(s))
print (tf)
unique_key test_ids status revenue cnt_days
0 1 1 passed 234.54 3
1 1 2 passed 543.21 5
2 2 11 failed 21.30 4
3 1 15 failed 2098.21 6
4 2 51 passed 232.00 21
5 2 75 failed 123.87 32