I have a dataframe and dictionary like as shown below
ID,Name,value,total,
1,Ajay,2.00,35
1,Dan,3.00,65
2,Ajay,2,78
2,Rajini,0.0,98
3,Ajay,3.00,53
3,Rad,75.25,21
df1 = pd.read_clipboard(sep=',')
output = {'Ajay': {1: 'ABC', 2: 'DEF', 3: 'DUMMA', 4: 'CHUMMA'}, 'Dan': {0: 'KOREA', 1: 'AUS/NZ', 2: 'INDIA', 3: 'ASEAN'}}
I would like to do the below
a) Replace the values in value column by matching Name value to Name key in nested dict.
For ex: ID=1 has Name as Ajay and value as 2.00.
Now, if we look at the dict, we Ajay outer key and trying to find the matching key (which is 2). So, we replace value 2.00 with DEF.
Similarly, we do this for other Name which is Dan.
I tried the below
df1.replace({"values": output},inplace=True) # doesn't work
for d in output.values():
print(d.key())
Is there any efficient and elegant way to do this sort of replacement for million rows dataframe?
I expect my output to be like as below
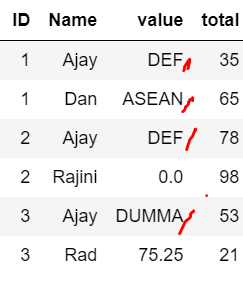
>Solution :
Use DataFrame.join with DataFrame.stack for new column and then use Series.fillna for replace not matched values by value column:
df = df.join(pd.DataFrame(output).stack().rename('new'), on=['value','Name'])
df['value'] = df.pop('new').fillna(df['value'])
print (df)
ID Name value total
0 1 Ajay DEF 35
1 1 Dan ASEAN 65
2 2 Ajay DEF 78
3 2 Rajini 0.0 98
4 3 Ajay DUMMA 53
5 3 Rad 75.25 21