As a Minimum Working Example, I have two datasets with 2 keys [col1 and col2] and multiple columns with data [columns starting with z_].
df1 = pd.DataFrame(data= {'col1': [1, 2], 'col2': ["A", "B"], 'z_col3': [3, np.nan], 'z_col4': [3, 4]} )
df2 = pd.DataFrame(data= {'col1': [1, 2], 'col2': ["C", "B"], 'z_col3': [3, 4], 'z_col4': [3, 4]} )
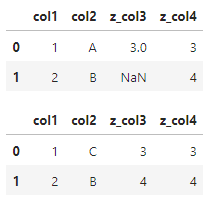
I want to do a merge where df1 with missing values in the z_ columns would get the values from df2. Is there any intelligent way to do so? This is a MWE so I have a quite large table with 50+ columns.
I tried the following but it yields an error:
df1[['z_col3','z_col4']] = df2[['col1','col2']].map(df2.set_index(['col1','col2'])[['z_col3','z_col4']])
Any idea on how to make it?
>Solution :
I would consider using a for loop with fillna() after filtering for the specific columns. Remember you can use fillna() rather than merge:
for x in [x for x in df if x.startswith('z')]:
df_1[x] = df_1[x].fillna(df_2[x])