I have the following dataframe:
df = pd.DataFrame({'Depth':['7500', '7800', '8300', '8500'],
'Gas':['25-13 PASON', '9/8 PASON', '19/14', '56/26'],
'ID':[1, 2, 3, 4]})
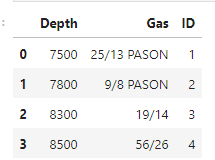
I want to add the word "PASON" to the end of any value in the Gas column that does not have it already, so that it ends up looking like this:
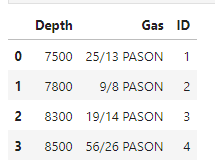
It should be a simple replace using Regex, but it doesn’t work. Here is my code:
df['Gas'] = df['Gas'].replace(to_replace =r'(\d+/\d+)(\t)(\d+)', value = r'\1 PASON\2', regex = True)
I’ve checked the Regex in a Regex checker, and it works fine there, but when I add it to Pandas it doesn’t work. What am I missing?
Thanks!
>Solution :
You can simply check for the substring ‘PASON’ and add if not present:
df['Gas'] = df['Gas'].where(df['Gas'].str.contains('PASON'), df['Gas'] + ' PASON')
giving
Depth Gas ID
0 7500 25-13 PASON 1
1 7800 9/8 PASON 2
2 8300 19/14 PASON 3
3 8500 56/26 PASON 4