I have the following DataFrame:
df = pd.DataFrame({'a': [0.28,0,0.25, 0.85, 0.1], 'b': [0.5,0.5,0, 0.75, 0.1], 'c':[0.33,0.7,0.25, 0.2, 0.5],
'd':[0,0.25,0.2, 0.66, 0.1]})
df
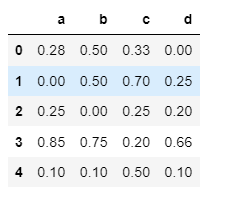
I would like to add a row ‘count’ at the end of the dataframe which is the sum of the max value of each row, but sum with its column. for example column b, it has only a max value in the first row, so the count of this column, in the end, is only 0.5, etc.
the results should look like this:
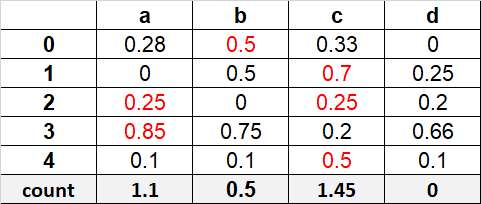
red cell represents a max value in this row
>Solution :
where
df.append(
df.where( # only look at values that are max for the row
df.eq( # compare max values to all values in row just in case there are more than 1
df.max(axis=1), # actually get max values
axis=0
)
).sum().rename('count')
)
a b c d
0 0.28 0.50 0.33 0.00
1 0.00 0.60 0.50 0.25
2 0.25 0.00 1.00 0.20
3 0.85 0.75 0.20 0.66
4 0.10 0.10 0.50 0.10
count 0.85 1.10 1.50 0.00