Assume I have this dataframe:
import pandas as pd
d = {"A" : [3,4,7,6,5,8,None,4,7],
"B" : ['a',None,'d',None,'j','u','k','k','z'],
"C" : [4,None,8,4,8,None,2,7,None],
"D" : [None,9,5,None,2,5,3,None,7],
"E": ['m','n','l',None,'s','g','s','u','a']}
df = pd.DataFrame(d)
################################
A B C D E
0 3.0 a 4.0 NaN m
1 4.0 None NaN 9.0 n
2 7.0 d 8.0 5.0 l
3 6.0 None 4.0 NaN None
4 5.0 j 8.0 2.0 s
5 8.0 u NaN 5.0 g
6 NaN k 2.0 3.0 s
7 4.0 k 7.0 NaN u
8 7.0 z NaN 7.0 a
What I need is a dictionary, which shows me all the possible combinations of columns with the percentage of empty (or filled) rows, something like this e.g.:
result = {2/9:["A","B","C","D","E"],
2/9:["A","B","C","E"],
...,
1/9:["A","C"]}
I’ve added also a little image to illustrate my problem:
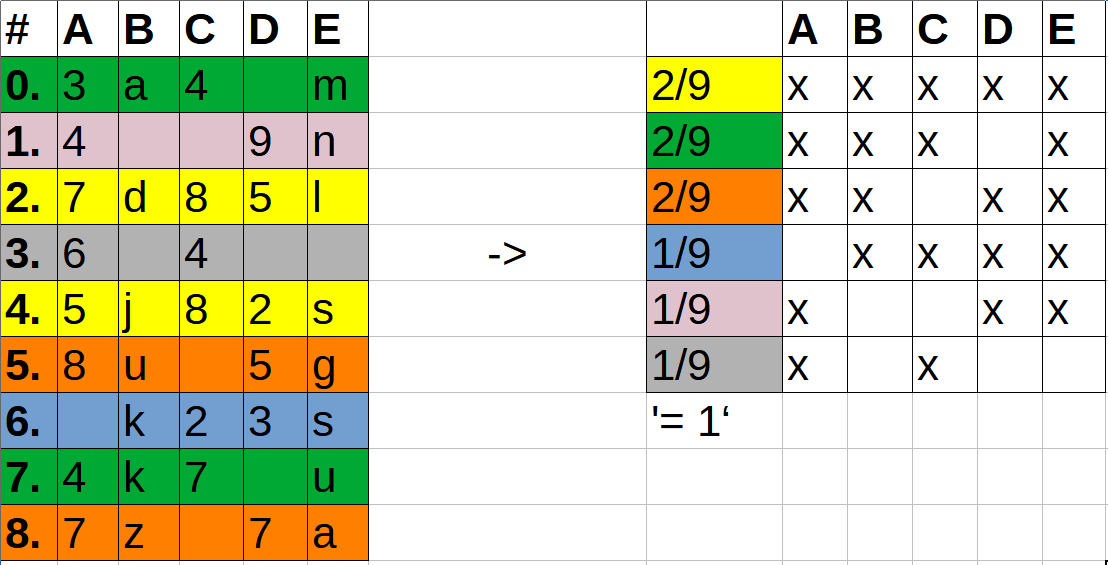
This would help me to proper slice and dice the dataframe according to the coverage of non-empty values. Thank you for your help!
>Solution :
Mask the data and you can groupby an count the rows with size:
out = (df.notnull()
.groupby(list(df)).size()
.div(len(df))
)
print(out.reset_index(name='pct'))
Output (False indicates a null value, True indicates a non-null)
A B C D E pct
0 False True True True True 0.111111
1 True False False True True 0.111111
2 True False True False False 0.111111
3 True True False True True 0.222222
4 True True True False True 0.222222
5 True True True True True 0.222222
If you want a dictionary, you can try:
{
tuple(df.columns[list(idx)]):val for idx, val in out.iteritems()
}
Output:
{('B', 'C', 'D', 'E'): 0.1111111111111111,
('A', 'D', 'E'): 0.1111111111111111,
('A', 'C'): 0.1111111111111111,
('A', 'B', 'D', 'E'): 0.2222222222222222,
('A', 'B', 'C', 'E'): 0.2222222222222222,
('A', 'B', 'C', 'D', 'E'): 0.2222222222222222
}