I want to replace np.nan values with other value in pandas.DataFrame using ‘apply’ function. And I will use replace method that where NaN is replaced with max value of each column (axis=0). You better understand below.
import pandas as pd
df = pd.DataFrame({'a':[1, np.nan, 3],
'b':[np.nan,5,6],
'c':[7,8,np.nan]})
result = df.apply(lambda c: c.replace(np.nan, max(c)), axis=0)
print(result)
There are three np.nan values. Two of them is replaced with appropriate values, but just one value is still np.nan(below picture)
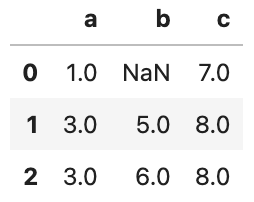
After setting argument axis to 1, there is still one value that isn’t replaced. What’s the reason?
>Solution :
Python’s max doesn’t work if a list starts with NaN; so max(df['b'])returns NaN and it cannot fill the NaN value in that column. Use c.max() instead (which works because by default Series.max skips NaNs). So:
df = df.apply(lambda c: c.replace(np.nan, c.max()), axis=0)
But instead of replace, you could use fillna on axis:
df = df.fillna(df.max(), axis=0)
Output:
a b c
0 1.0 6.0 7.0
1 3.0 5.0 8.0
2 3.0 6.0 8.0