I have a tricky question for you concerning data structure in pandas for plotting with seaborn.
Let’s imagine, I have several experiments, each of them performed in different conditions. The result of each experiment is an array with a few thousand floats.
I was considering to have all the experiment results stored in a single pandas dataframe, in the so-called long-format, i.e. each row is one experiment, and each column is a variable.
Almost all the variables are used to define the experimental conditions and then one variable containing the array of float with experiment results.
Something like this:
df = pd.DataFrame({'id':[1,2], 'temp':[21,22], 'oven':[0,1], 'values':[[1,2,3,4,5], [10,11,12,12,15,16,17]]})
So far so good.
Now I would like to use seaborn to make some plots. Imagine I want to plot an histogram of the values using id as a category.
I would do:
sns.histplot(df, x='values', hue='id')
But if I do so, I get an error message complaining that list is an unhashable type.
As a workaround, I changed the data structure, so that I have a row for each of the floats in the experiment results, but this is making the table unnecessarily huge.
Do you have any suggestion for me?
Thanks in advance
toto
>Solution :
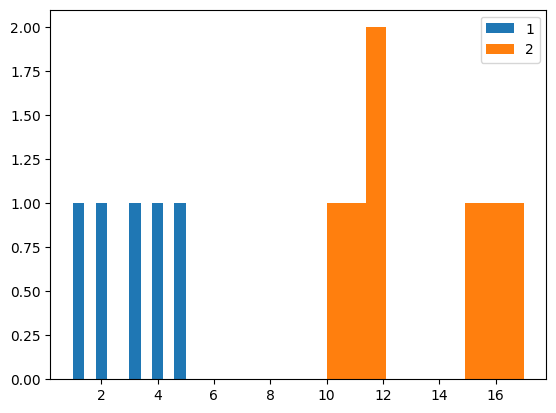
A flat/tidy DataFrame would be almost the same, but having one row per point.
If you explode your dataset, this would work:
df_flat = df.explode('values')
sns.histplot(df_flat, x='values', hue='id')
Output:

Another option, would be to build a dictionary:
sns.histplot(dict(zip(df['id'], df['values'])))
# or
sns.histplot({k: v.squeeze() for k,v in df.groupby('id')['values']})
Output:

Finally, you can always plot manually:
ax = plt.subplot()
for row in df.index:
ax.hist(df.loc[row, 'values'], label=df.loc[row, 'id'])
ax.legend()