I have Pyspark Dataframe named df as below,
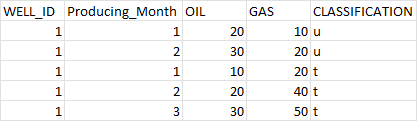
I need to pivot the data based on ProducingMonth and classification column and need to produce the following output

I am using the following pyspark code
pivotDF = df.groupBy("WELL_ID","CLASSIFICATION").pivot("CLASSIFICATION")
while I am displaying the data I am getting error "’GroupedData’ object has no attribute ‘display’"
>Solution :
You need to perform the aggregation after.
from pyspark.sql import functions as F
pivotDF = df.groupBy("WELL_ID","producing_month").pivot("CLASSIFICATION").agg(
F.first("OIL"),
F.first("GAS"),
)
Then you can probably use display pivotDF.display()