Here are the .txt files where the colon represents the beginning of the file:
City.txt:
New York
Chicago
Sacramento
County.txt:
New York County
Chicago County
Sacramento County
State.txt:
New York
Illinois
California
Here is my code so far:
columnCity1 = open('City.txt', 'r')
columnCounty2 = open('County.txt', 'r')
columnState3 = open('State.txt', 'r')
This imports the files and creates them as a list (to my understanding)
The desired outcome would be:
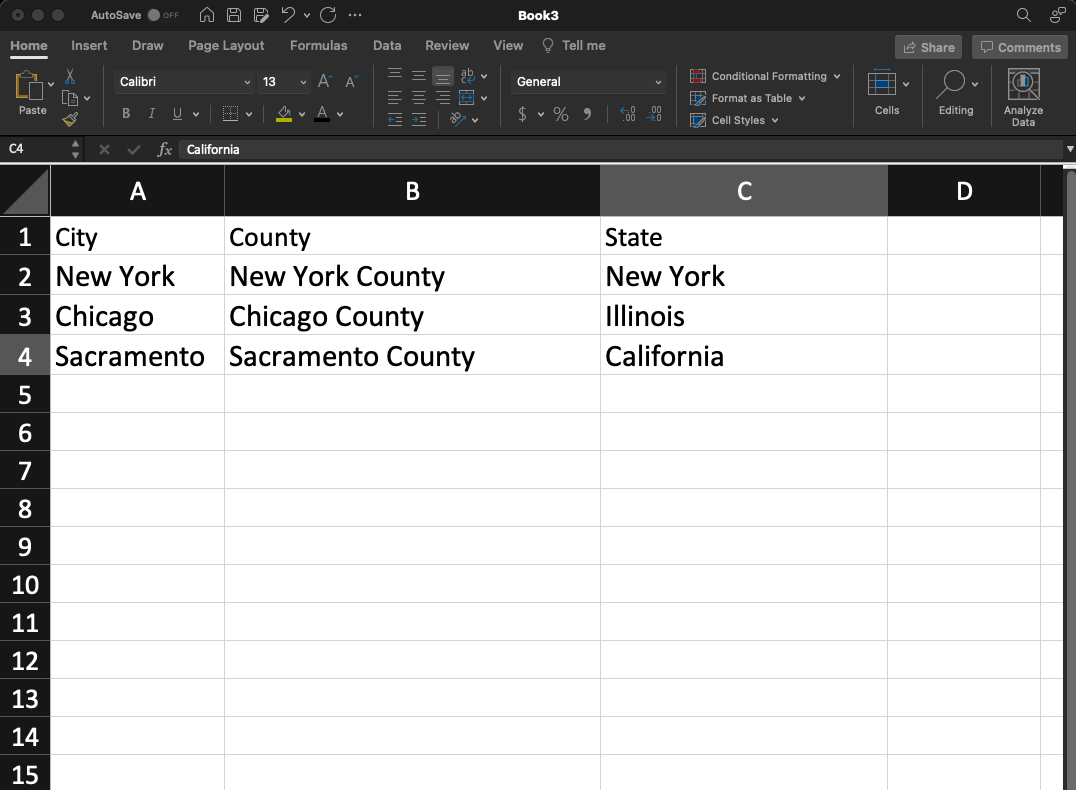
>Solution :
Under assumption that csv file can be used for Excel and you can reformat it if needed or just open, here’s a Pandas solution (you’ll need Pandas installed):
import pandas as pd
def read_files():
# Read all lines, get rid of empty entries and next line characters
with open('./city.txt', 'r') as f:
cities = [c.rstrip() for c in f.readlines() if len(c.rstrip())]
with open('./county.txt', 'r') as f:
counties = [c.rstrip() for c in f.readlines() if len(c.rstrip())]
with open('./state.txt', 'r') as f:
states = [s.rstrip() for s in f.readlines() if len(s.rstrip())]
# Create dataframe
df = pd.DataFrame(columns=['City', 'County', 'State'])
# Go over cities, countries and states - place in DataFrame
for group in zip(cities, counties, states):
df.loc[len(df)] = group
# Save to csv file - reformat to excel if different format needed.
filename = 'results.csv'
df.to_csv(filename)
#Call the above function - check the resulting file for output.
read_files()