I need the most similar (max count) from column cluster-1 from column cluster-2.
Input – data
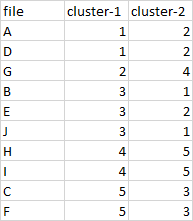
Output – data
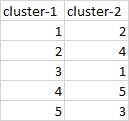
I use the command: df.groupby([‘cluster-1′,’cluster-2’])[‘cluster-2’].count() this command will give me count per occurrence in the column cluster-2. I need advice on how to proceed, thanks.
>Solution :
Use SeriesGroupBy.value_counts because by default sorted values, so possible convert MultiIndex to DataFrame by MultiIndex.to_frame and then remove duplicates by cluster-1 in DataFrame.drop_duplicates:
df1 = (df.groupby(['cluster-1'])['cluster-2']
.value_counts()
.index
.to_frame(index=False)
.drop_duplicates('cluster-1'))