I am splitting a xlsm file ( with multiple sheets) into a csv with each sheet as a separate csv file. In the process I am removing first 4 lines and keeping the header only which start from row 5.
Here is the input file
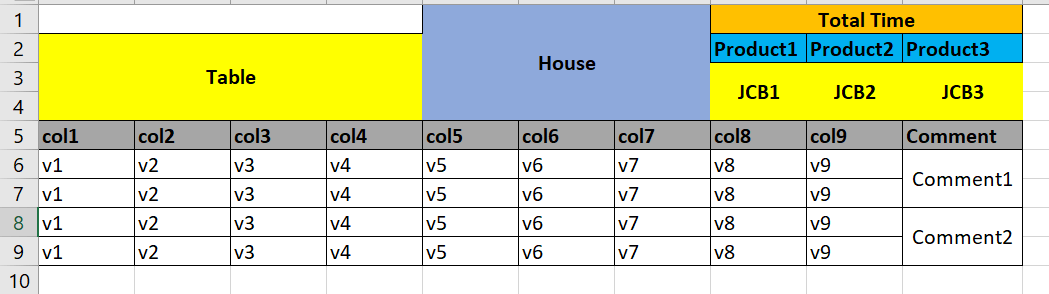
This is the output I expect –

But I am getting the below output –

Here is the code I am using –
import pandas as pd
xl = pd.ExcelFile('Sample_File.xlsm')
for sheet in xl.sheet_names:
df = pd.read_excel(xl,sheet_name=sheet)
df1 = df.iloc[3:]
df1.to_csv(f"{sheet}.csv",index=False)
How can I remove the first row which is having values from unnamed: 0 to unnamed: 9?
Also how can I have comment1 show up in both (First and second row) and comment2 in (Third and Fourth row) in last column?
>Solution :
You need to use the skiprows argument inside the pd.read_excel function to correctly get the column names in the 5th row.
import pandas as pd
xl = pd.ExcelFile('Sample_File.xlsm')
for sheet in xl.sheet_names:
df = pd.read_excel(xl, sheet_name=sheet, skiprows=4)
# no more iloc here
df.to_csv(f'{sheet}.csv', index=False)