I am attempting to fetch an API using Python requests.
The API is documented here: https://consumerdatastandardsaustralia.github.io/standards/#get-data-holder-brands
The following request works on reqbin:
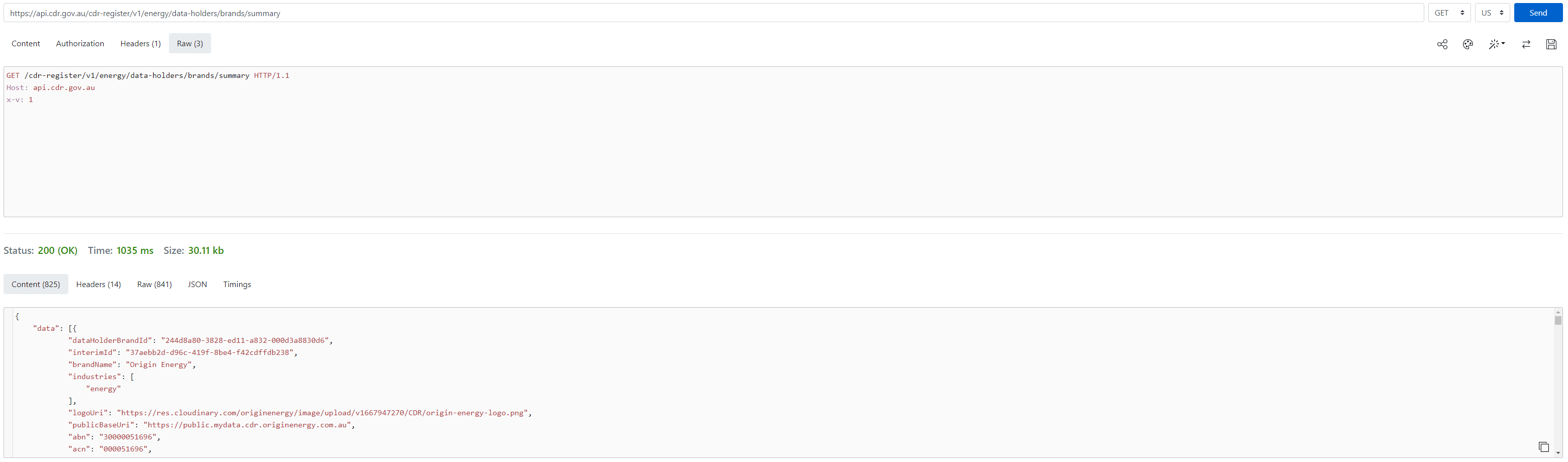
I have the following Python code
import requests
r = requests.get('https://api.cdr.gov.au/cdr-register/v1/energy/data-holders/brands/summary', headers={"x-v":"1"})
print(r.content)
This returns a 403 error, I’m not sure what other difference there could be between the two requests which could result in such an error.
b'<html>\r\n<head><title>403 Forbidden</title></head>\r\n<body>\r\n<center><h1>403 Forbidden</h1></center>\r\n<hr><center>Microsoft-Azure-Application-Gateway/v2</center>\r\n</body>\r\n</html>\r\n'
I thought it could have to do with the Authorization header for the API which wants a RFC6750 token however that doesn’t explain why the reqbin works without one.
>Solution :
Try to add User-Agent header:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/117.0",
"x-v": "1",
}
r = requests.get(
"https://api.cdr.gov.au/cdr-register/v1/energy/data-holders/brands/summary",
headers=headers,
)
print(r.content)
Prints:
b'{\r\n "data": [\r\n {\r\n "dataHolderBrandId":
...