I have a data set of about 300 points, each with a corresponding X value and Y value. There is also a third column in the data with a "Quality" label, either saying "Good" or "Bad", and so there are three columns of data in my data frame, 2 are numeric, and one is string.
I simply want to make a scatter plot of these data points, with the "Good" points in blue and the "Bad" points in red, with a legend showing me this color distinction. Yet I am just not able to match in python the plot I was able to make in Excel.
In Excel, I simply made a scatter plot of the X and Y columns and got this, which looks correct to me:
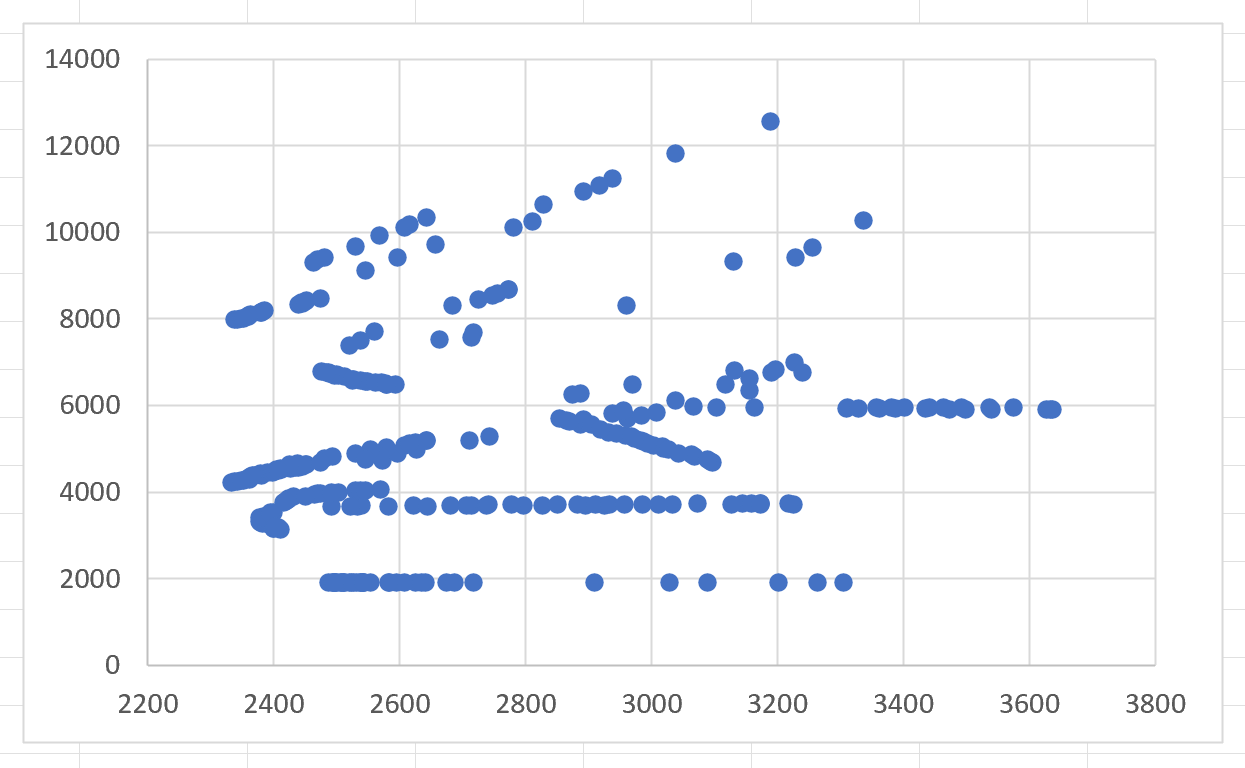
I then try to create this plot in python using the following code:
x = df['X']
y = df['Y']
plt.scatter(x, y)
plt.show()
And I get this mess of a plot which is confusing me:
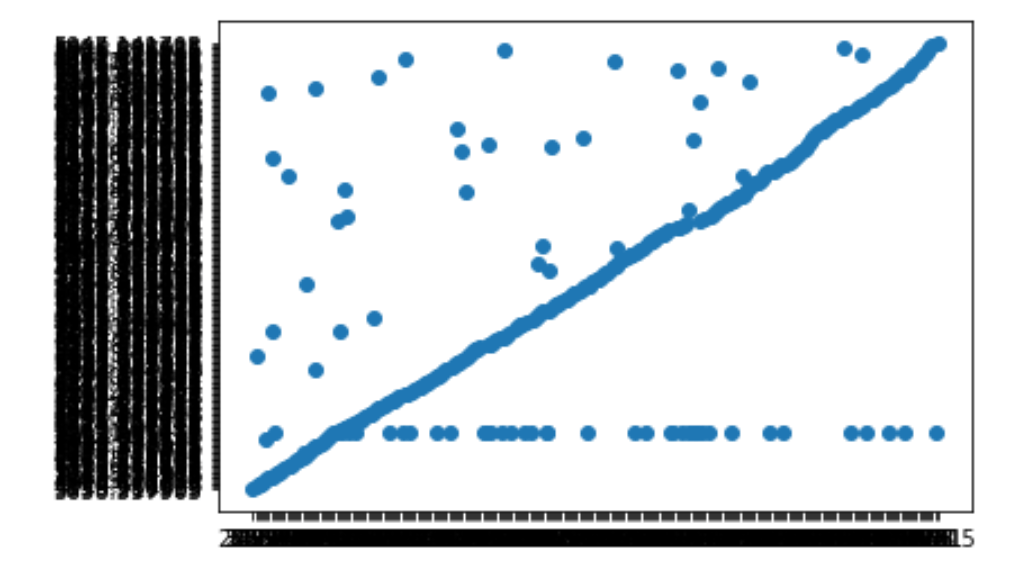
Beyond the axis tick marks looking horribly crammed together, the data points are not making any sense to me at all, they do not at all resemble the Excel plot I made, which is using the exact same data. Maybe this could be an axis formatting issue, but I do not know.
How can I fix my code to properly capture the data points shown in my Excel plot?
>Solution :
Assuming you have read your data into a pandas dataframe with df = pd.read_csv("/path/to/your/file"), and it has three columns as: X, Y, and Quality, the following should do the trick for you:
# Separate the data into two groups based on the 'Quality' column
good_data = df[df['Quality'] == 'Good']
bad_data = df[df['Quality'] == 'Bad']
# Create a scatter plot
plt.scatter(good_data['X'], good_data['Y'], color='blue', label='Good')
plt.scatter(bad_data['X'], bad_data['Y'], color='red', label='Bad')
# Adding labels and title (optional)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Scatter Plot of Good vs Bad Quality Data')
# Show the legend
plt.legend()
# Show the plot
plt.show()