So, I created a Python script to batch convert PDF files using Ghostscript. Ideally it should work, but I am not sure why it isn’t working. For now, it is going through the input PDF files twice and when it runs the second time, it overwrites the output files.
Here’s the script.
from __future__ import print_function
import os
import subprocess
try:
os.mkdir('compressed')
except FileExistsError:
pass
for root, dirs, files in os.walk("."):
for file in files:
if file.endswith(".pdf"):
filename = os.path.join(root, file)
arg1= '-sOutputFile=' + './compressed/' + file
print ("compressing:", file )
p = subprocess.Popen(['gs', '-sDEVICE=pdfwrite', '-dCompatibilityLevel=1.4', '-dPDFSETTINGS=/screen', '-dNOPAUSE', '-dBATCH', '-dQUIET', str(arg1), filename], stdout=subprocess.PIPE).wait()
Here’s the ouput.
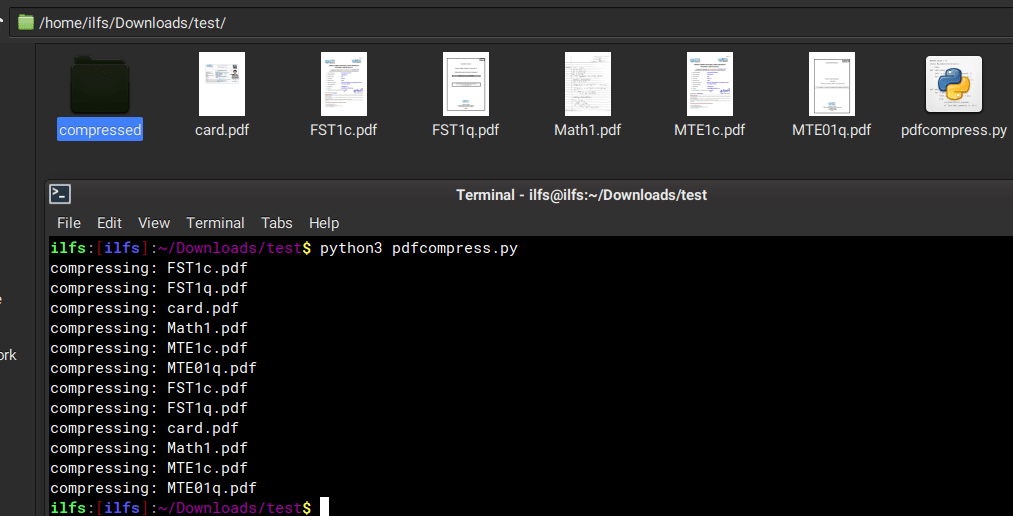
I am missing what did I do wrong.
>Solution :
file is just the name of the file. You have several files called the same in different directories. Don’t forget that os.walk recurses in subdirectories by default.
So you have to save the converted files in a directory or name which depends on root.
and put the output directory outside the current directory as os.walk will scan it
For instance, for flat output replace:
arg1= '-sOutputFile=' + './compressed/' + file
by
arg1= '-sOutputFile=' + '/somewhere/else/compressed/' + root.strip(".").replace(os.sep,"_")+"_"+file
The expression
root.strip(".").replace(os.sep,"_")
should create a "flat" version of root tree without current directory (no dot) and path separators converted to underscores, plus one final underscore. That’s one option that would work.
An alternate version that won’t scan ./compressed or any other subdirectory (maybe more what you’re looking for) would be using os.listdir instead (no recursion)
root = "."
for file in os.listdir(root):
if file.endswith(".pdf"):
filename = os.path.join(root, file)
arg1= '-sOutputFile=' + './compressed/' + file
print ("compressing:", file )