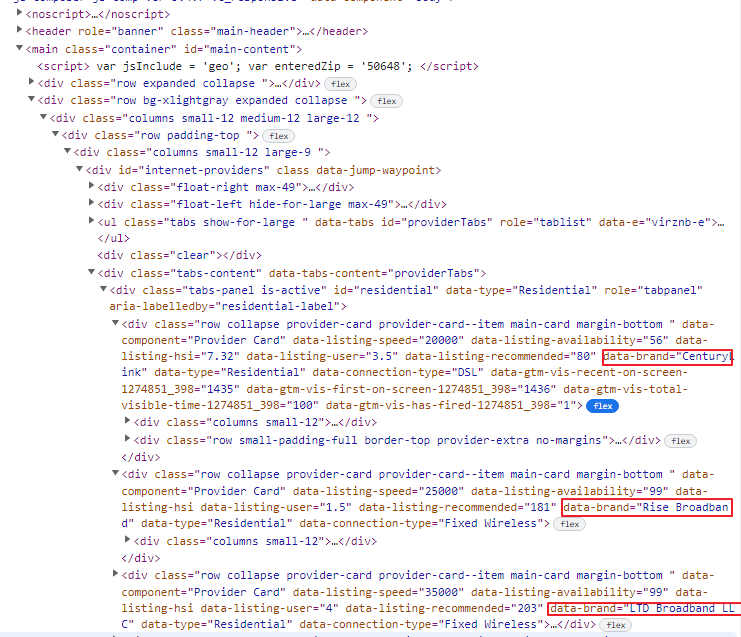
I’m trying to grab a div tag in an html page, but the result is showing an empty list. I’ve provided the code and a picture of the html. The page_text variable is an empty list.
url = 'https://www.highspeedinternet.com/in-your-area?zip=50648'
page = requests.get(url).text
doc = BeautifulSoup(page, "html.parser")
page_text = doc.find_all("div", {"data-brand"})
print(page_text)
>Solution :
You are close to your goal, just add True as value in your dict:
doc.find_all('div',{"data-brand":True})
As alternative you can go with css selectors and list comprehension to get all the values:
[e.get('data-brand') for e in doc.select('div[data-brand]')]
Output:
['CenturyLink', 'Rise Broadband', 'LTD Broadband LLC', 'Viasat', 'HughesNet', 'Heartland Technology', 'Ooma', 'CenturyLink', 'Rise Broadband', 'LTD Broadband LLC', 'Viasat', 'HughesNet', 'Ooma', 'Heartland Technology', 'T-Mobile', 'Verizon Wireless', 'AT&T Wireless', 'Mint', 'Visible']